


OCR steht für Optical Character Recognition (optische Zeichenerkennung). Hierbei handelt es sich um eine weit verbreitete Technologie zur Erkennung von Text in Bildern, z. B. in gescannten Dokumenten und Fotos.
Nach dem Ausführen von OCR können Sie mit PDFelement gescannte und bildbasierte PDF-Dateien so einfach bearbeiten wie ein Word-Dokument. Wenn Sie neuen Text hinzufügen, entspricht dieser dem Aussehen der Originalschriftarten in der gescannten PDF-Datei oder im Bild.
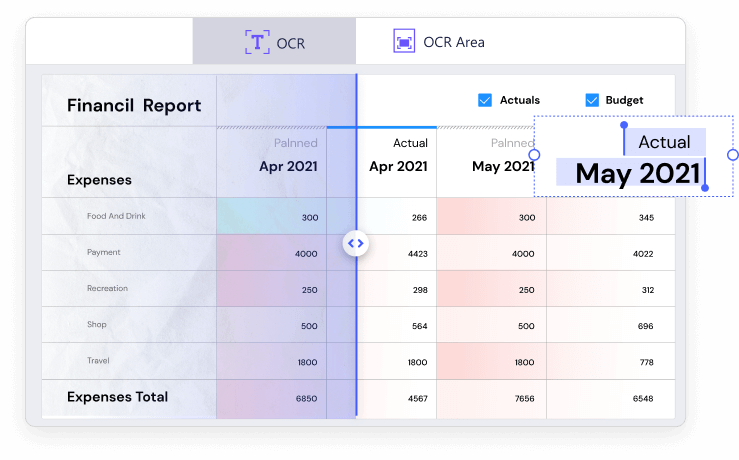
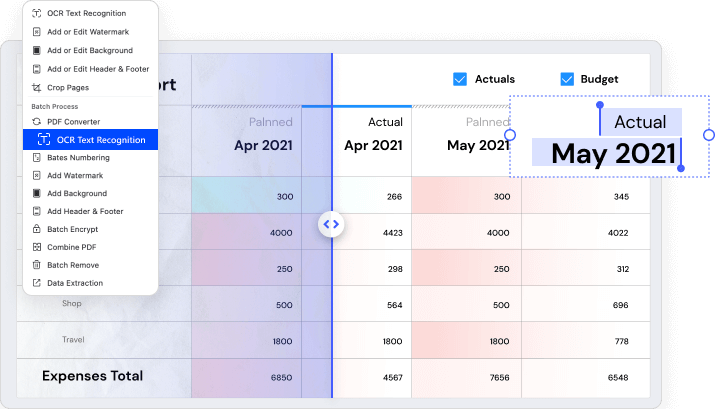
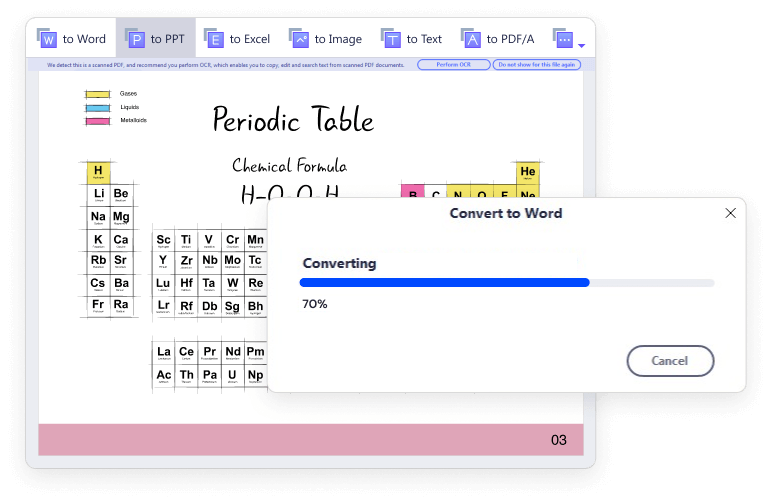
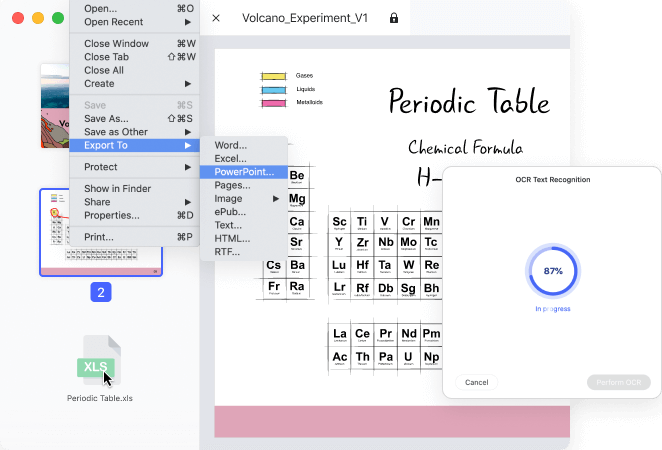
Mit der OCR-Funktion in Wondershare PDFelement können Sie gescannte und bildbasierte PDF-Dateien einfach in verschiedene Formate mit bearbeitbarem, auswählbarem und durchsuchbarem Inhalt konvertieren, z. B. Microsoft Office-Formate, PPT, Pages oder einfache Textdokumente (TXT-Dateien).
Die manuelle Dateneingabe gehört für Sie bald der Vergangenheit an. Mit PDFelement können Sie Daten aus gescannten und bildbasierten PDF-Dateien mit ausgewählten Bereichen extrahieren oder Daten aus Formularfeldern in PDF-Dateien extrahieren, nachdem Sie OCR ausgeführt haben.
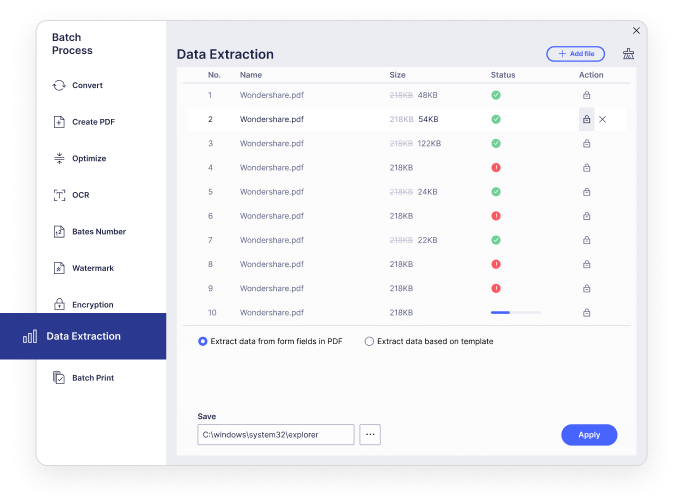
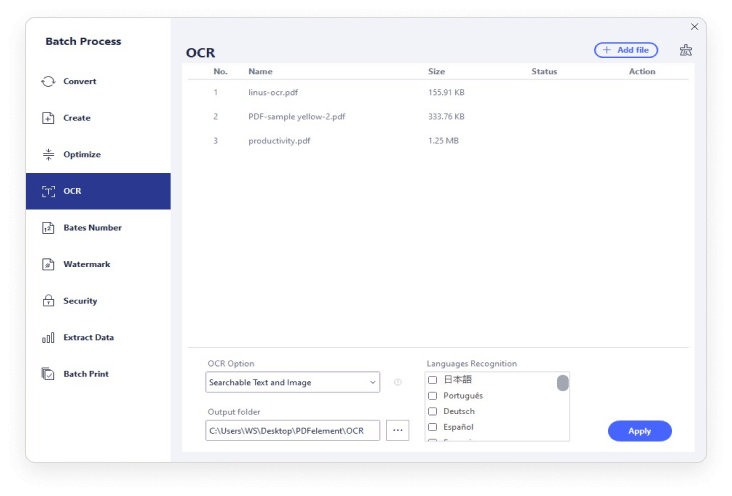
Was tun Sie, wenn Sie gescannte Dokumente und reine Bilddateien im PDF-Format im Stapelformat für einen wichtigen Fall durchsuchen müssen? Mit der Stapel-OCR-Funktion von PDFelement können Sie mehrere gescannte oder bildbasierte PDF-Dateien in editierbare und durchsuchbare PDF-Dateien konvertieren.
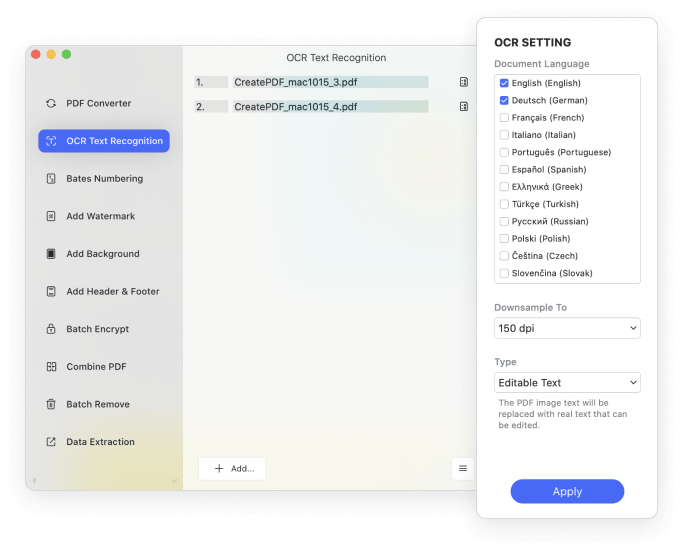
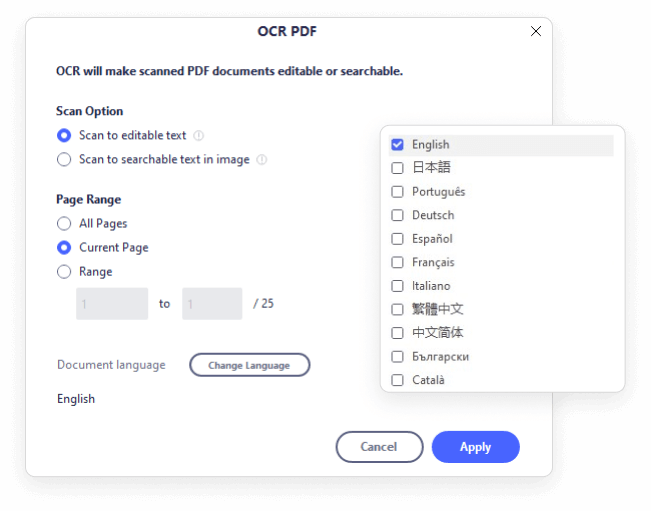
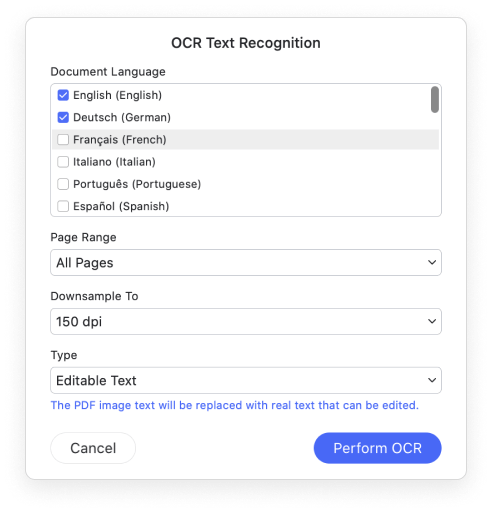
Die OCR-Funktion von PDFelement unterstützt Dutzende von Sprachen, z. B. Englisch, Portugiesisch, Japanisch, Spanisch, Deutsch, Italienisch, Französisch, Bulgarisch, Chinesisch (vereinfacht), Chinesisch (traditionell), Kroatisch, Katalanisch und weitere Sprachen.
Der einfachste Weg zum Erstellen, Bearbeiten, Konvertieren und Signieren von PDF-Dokumenten.
Bearbeiten, zusammenführen, organisieren, komprimieren, signieren und sichern Sie Ihre Dokumente überall.
Verarbeiten Sie PDF-Dokumente unter Windows und iOS mit dem perfekten Multi-Terminal-Cloud-Erlebnis.




