
Haben Sie schon einmal auf ein Bild mit Text gestarrt und sich gewünscht, Sie könnten ihn einfach extrahieren und bearbeiten? Ob es sich um ein gescanntes Dokument, einen Screenshot oder ein Foto von einem Whiteboard handelt, das manuelle Eingeben des Textes kann zeitaufwändig und fehleranfällig sein. Hier kommt DeepSeek ins Spiel, dieser brandneue und leistungsstarke KI-Chatbot, mit dem Sie die Textextraktion aus Bildern vereinfachen können.
In diesem Leitfaden erfahren Sie, wie Sie mit DeepSeek mühelos Text extrahieren können, und wir stellen Ihnen PDFelement vor, ein vielseitiges Tool, das Ihren Workflow bei der Dokumentenverwaltung verbessert.
Hier kommt PDFelement ins Spiel, eine hochmoderne PDF-Lösung. Mit PDFelement können Sie DeepSeek-Chats schnell und effizient in PDF konvertieren, wobei alle wichtigen Details erhalten bleiben und die Benutzerfreundlichkeit verbessert wird.
In diesem Artikel
- DeepSeek für OCR - Überblick
- Wie man mit DeepSeek Text aus Bildern extrahiert
- Vorstellung von PDFelement - Verbessern Sie Ihren Workflow für die Textextraktion
- Warum PDFelement für die Textextraktion wählen?
- Wie man Text aus PDFs extrahiert
- Wie man Text aus Bildern in PDF extrahiert
- DeepSeek vs. PDFelement - Was ist besser für die Textextraktion?
DeepSeek für OCR - Überblick
DeepSeek nutzt die KI, um Text mit hoher Genauigkeit aus Bildern zu extrahieren. Egal, ob Sie mit gescannten Dokumenten, Fotos oder Screenshots arbeiten, DeepSeek kann den Text in diesen Bildern schnell in bearbeitbare und durchsuchbare Formate konvertieren
Wichtigste Funktionen von DeepSeek OCR:
- DeepSeek Bild zu Text: Extrahieren Sie Text aus Bildern in Sekundenschnelle.
- DeepSeek Bild lesen: Präzise Erkennung von Text aus komplexen Layouts, handschriftlichen Notizen oder Bildern mit schlechter Qualität.
- Effizienz: Sparen Sie Zeit, indem Sie die Textextraktion mit KI-gestützter Erkennung automatisieren.
Wenn Sie die OCR-Funktionen von DeepSeek nutzen, können Sie Zeit sparen, den manuellen Aufwand reduzieren und die Produktivität steigern.
Wie man mit DeepSeek Text aus Bildern extrahiert
Das Extrahieren von Text aus Bildern mit DeepSeek ist ein unkomplizierter Prozess. Hier finden Sie eine Schritt-für-Schritt-Anleitung für den Anfang:
Schritt 1 Hochladen Ihres Bildes
Laden Sie zunächst die Bilddatei hoch, aus der Sie den Text extrahieren möchten. DeepSeek unterstützt verschiedene Bildformate, darunter JPEG, PNG und BMP.
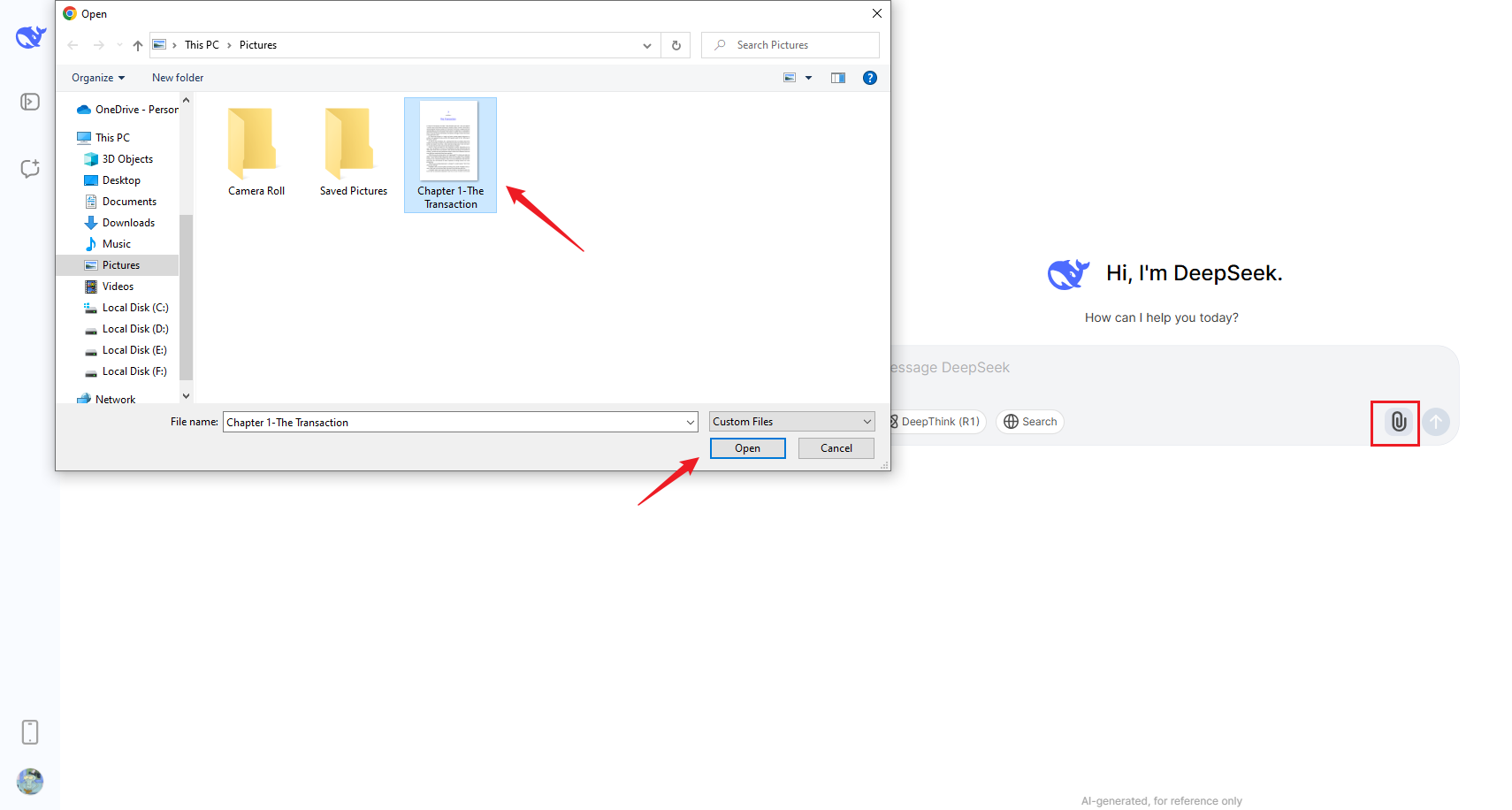
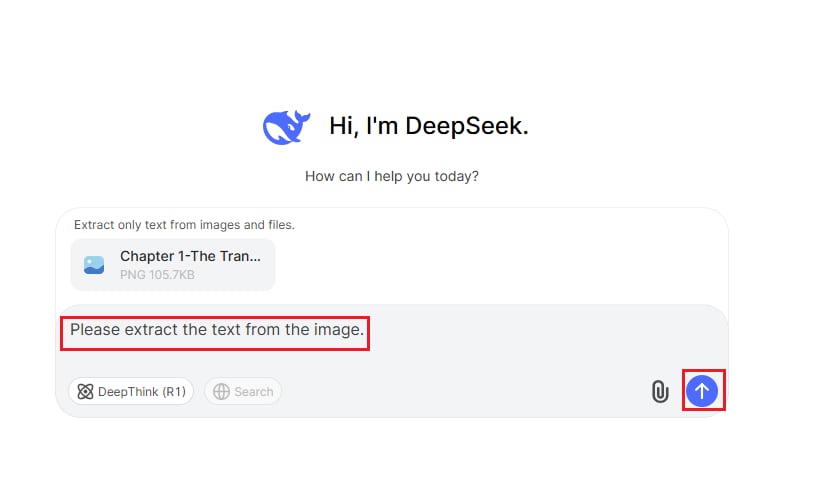
Schritt 2 Prompt eingeben und OCR ausführen
Geben Sie den Prompt ein, z.B. „Extrahiere den Text aus dem Bild“, und verwenden Sie dann die KI von DeepSeek, um das Bild zu verarbeiten und den Text zu extrahieren.
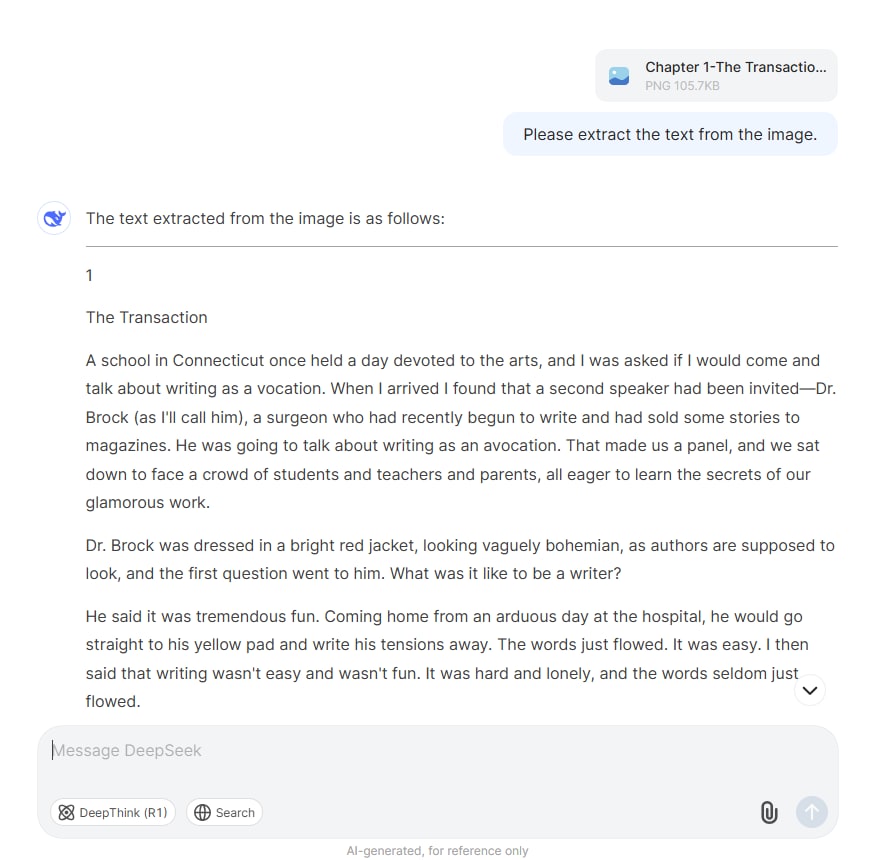
Schritt 3 Review und Bearbeitung
Überprüfen Sie den extrahierten Text auf Richtigkeit und nehmen Sie die notwendigen Anpassungen vor.
Schritt 4 Exportieren und verwenden
Kopieren Sie den Text und verwenden Sie ihn in Dokumenten, Berichten oder jedem anderen gewünschten Format.
Vorstellung von PDFelement - Verbessern Sie Ihren Workflow für die Textextraktion
Während DeepSeek bei der Konvertierung von Bildern in Text überragend ist, bietet PDFelement eine robuste Lösung für die Bearbeitung von extrahiertem Text in Dokumenten. PDFelement bietet ein KI-gestütztes OCR-Tool für die Extraktion von Text aus Bildern und gescannten PDFs und sorgt so für eine reibungsloses Dokumentenverwaltung.
Wichtigste Funktionen von PDFelement:
- OCR für gescannte PDFs: Extrahieren Sie Text aus gescannten PDFs und Bildern präzise.
- PDF bearbeiten: Ändern Sie Text, Bilder und Layouts mühelos.
- PDF annotieren: Fügen Sie Kommentare, Hervorhebungen und Notizen hinzu.
- PDF konvertieren: Exportieren Sie Dokumente in Word, Excel und andere Formate.
Mit PDFelement können Sie Ihren Workflow rationalisieren und alle Ihre Dokumentanforderungen auf einer einzigen Plattform abwickeln.
Warum PDFelement für die Textextraktion wählen?
PDFelement zeichnet sich als leistungsstarkes Tool für die Textextraktion und die Dokumentenverwaltung aus. Hier ist der Grund dafür:
1. Genauigkeit:
Die KI-gestützte OCR von PDFelement sorgt für eine präzise Textextraktion, selbst bei schlechter Bildqualität oder komplexen Layouts.
2. Benutzerfreundlichkeit:
Die benutzerfreundliche Oberfläche erleichtert das Extrahieren, Bearbeiten und Verwalten von Text ohne große Lernkurve.
3. Vielseitigkeit:
PDFelement ist mehr als nur ein OCR Tool. Es ist eine All-in-One-Lösung zum Bearbeiten, Kommentieren und Konvertieren von Dokumenten.
4. Kostengünstig:
Im Vergleich zu anderen Tools bietet PDFelement fortschrittliche Funktionen zu einem erschwinglichen Preis, was es zu einer guten Wahl für Privatpersonen und Unternehmen gleichermaßen macht.
Wie man Text aus PDFs extrahiert
Die folgenden Schritte beschreiben, wie Sie mit PDFelement Text aus einem PDF extrahieren.
Schritt 1 PDF-Dateien hinzufügen
Laden Sie PDFelement herunter und installieren Sie es. Öffnen Sie dann die PDF-Dateien, aus denen Sie Text extrahieren möchten.
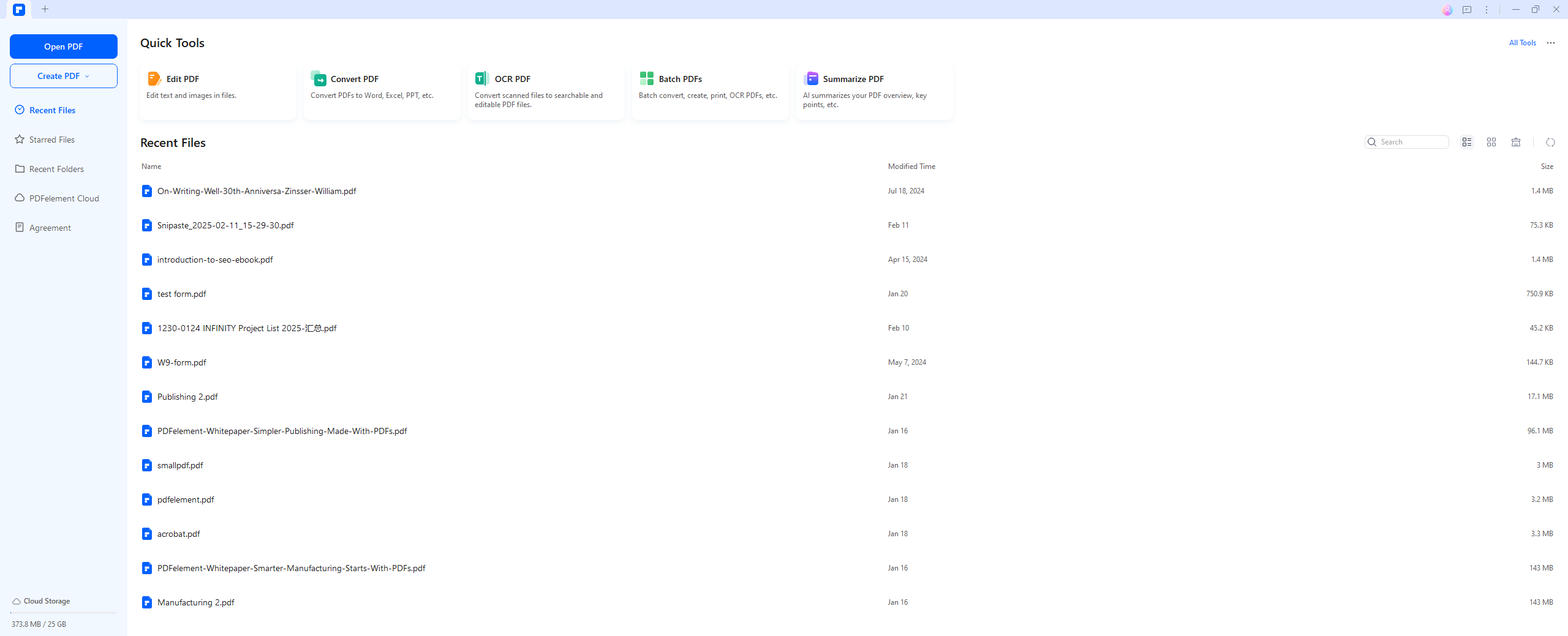
Schritt 2 Text aus PDF extrahieren
Nachdem Sie die Datei geöffnet haben, klicken Sie auf die Registerkarte „Bearbeiten“ und wählen das „Bearbeiten“ Symbol. Klicken Sie dann mit der rechten Maustaste auf den Text, wählen Sie „Kopieren“ und extrahieren Sie den gewünschten Text.
Wie man Text aus Bildern in PDF extrahiert
Um Text aus Bildern in Ihrem PDF zu extrahieren, folgen Sie diesen Schritten in PDFelement.
Schritt 1 Ihr bildbasiertes PDF öffnen
Sobald Sie PDFelement installiert haben, öffnen Sie das Programm, um die OCR für Ihre PDF-Datei durchzuführen. Klicken Sie auf „Dateien öffnen“, um die gescannte Datei auszuwählen und zu öffnen.
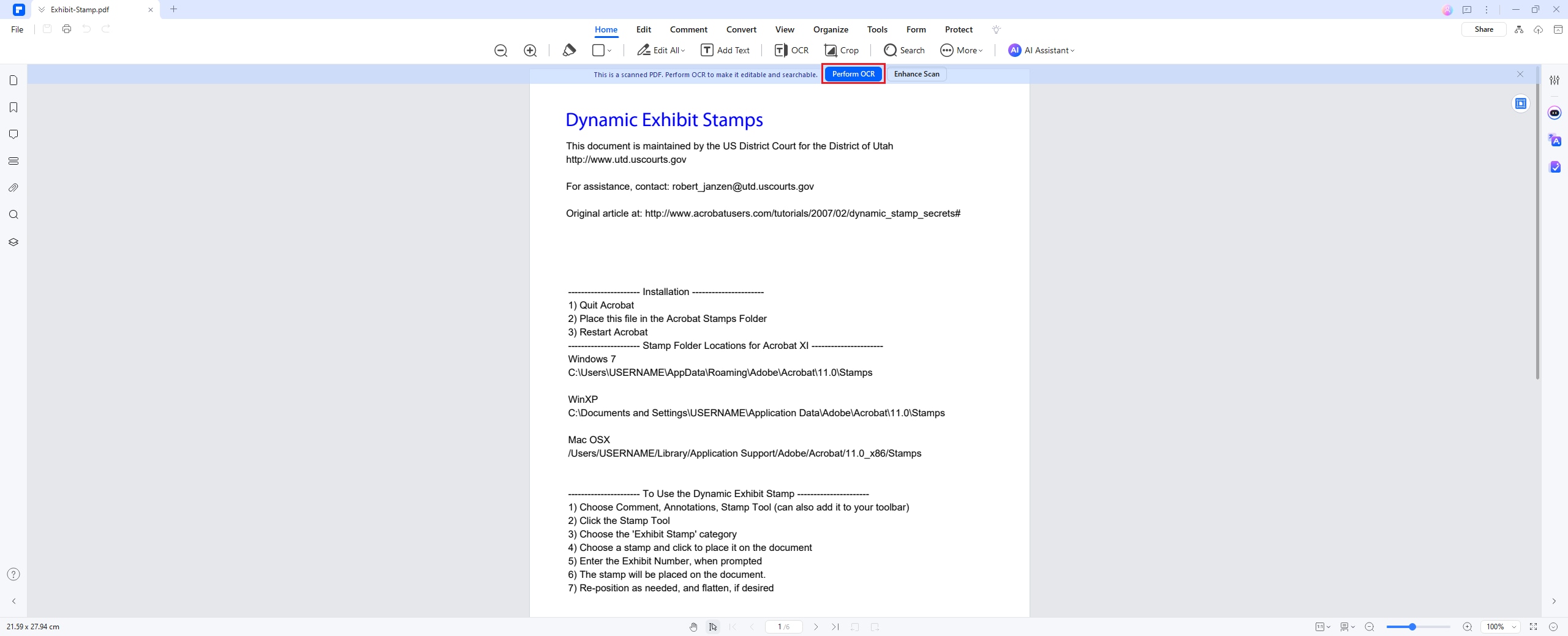
Schritt 2 OCR durchführen
Nachdem Sie die Datei im Programm geöffnet haben, erkennt das Programm, dass es sich um ein gescanntes Dokument handelt und schlägt vor, dass Sie eine OCR durchführen müssen. Klicken Sie auf die Option „OCR durchführen“ in der oberen blauen Leiste, wählen Sie dann eine OCR-Sprache und klicken Sie auf „OK“. Standardmäßig ist sie auf Englisch eingestellt, aber Sie können sie ändern.
Schritt 3 Text aus einem Bild-PDF extrahieren
Nach Abschluss der OCR können Sie Text aus Ihrem PDF extrahieren. Gehen Sie dazu auf die Registerkarte „Bearbeiten“ und klicken Sie oben rechts auf die „Bearbeiten“ Schaltfläche. Markieren Sie den Text, den Sie extrahieren möchten, klicken Sie dann mit der rechten Maustaste und wählen Sie „Kopieren“.
Nach Abschluss der OCR können Sie Text aus Ihrem PDF extrahieren. Gehen Sie dazu auf die Registerkarte „Bearbeiten“ und klicken Sie oben rechts auf die „Bearbeiten“ Schaltfläche. Markieren Sie den Text, den Sie extrahieren möchten, klicken Sie dann mit der rechten Maustaste und wählen Sie „Kopieren“.
DeepSeek vs. PDFelement - Was ist besser für die Textextraktion?
Sowohl DeepSeek als auch PDFelement bieten leistungsstarke Funktionen zur Textextraktion, aber sie zeichnen sich durch unterschiedliche Szenarien aus:
- DeepSeek: Ideal für schnelle, einmalige Textextraktionsaufgaben, insbesondere bei der Arbeit mit Bildern.
- PDFelement: Am besten geeignet für eine umfassende Dokumentenverwaltung, einschließlich OCR, Bearbeitung und Konvertierung.
Wenn Sie ein Tool suchen, das Textextraktion mit fortschrittlicher Dokumentenverarbeitung kombiniert, ist PDFelement der klare Sieger.
Fazit
DeepSeek vereinfacht die Textextraktion aus Bildern mit KI-gestützter OCR und ist damit ein wertvolles Tool für die schnelle Konvertierung von Text. PDFelement bietet jedoch zusätzliche Funktionen wie OCR, Textbearbeitung, Anmerkungen und Formatkonvertierung für eine vollständige Dokumentenverwaltungslösung.
Sind Sie bereit, Ihren Prozess der Textextraktion zu optimieren? Probieren Sie Wondershare PDFelement noch heute aus und profitieren Sie von reibungsloser Dokumentenbearbeitung und erhöhter Produktivität.
 G2-Wertung: 4.5/5 |
G2-Wertung: 4.5/5 |  100 % Sicher |
100 % Sicher |
 G2-Wertung: 4.5/5 |100 % Sicher |
G2-Wertung: 4.5/5 |100 % Sicher |