
In der heutigen datengesteuerten Welt kann die Extraktion von Informationen aus PDF-Dokumenten zeitaufwändig und fehleranfällig sein. Das manuelle Kopieren und Einfügen von Daten aus Hunderten oder Tausenden von PDF-Dateien ist mühsam und kann zu Ungenauigkeiten und Inkonsistenzen in Ihren Daten führen. Mit der Kraft der Automatisierung können Sie jedoch Ihren Prozess der PDF-Datenextraktion rationalisieren und sich wertvolle Zeit und Mühe sparen.
Die Automatisierung der PDF-Datenextraktion kann viele Vorteile bieten, von verbesserter Genauigkeit und Effizienz bis hin zu höherer Produktivität und Skalierbarkeit. Indem Sie die manuelle Dateneingabe überflüssig machen, verringern Sie das Risiko von Fehlern und gewinnen Zeit, um sich auf höherwertige Aufgaben zu konzentrieren. In diesem Artikel erläutern wir Ihnen Schritt für Schritt, wie Sie die Extraktion von PDF-Daten automatisieren können.

Vorteile der automatischen Extraktion von Daten aus PDF
Die Automatisierung der PDF-Datenextraktion kann verschiedene Vorteile bieten und ist daher ein wertvolles Tool für Unternehmen und Privatpersonen. Indem Sie den Zeit- und Arbeitsaufwand für die Extraktion von Daten aus PDF-Dokumenten reduzieren, können Sie Ihren Workflow verbessern und bessere Ergebnisse erzielen. Hier sind einige der wichtigsten Vorteile der automatisierten PDF-Datenextraktion:
Zeitersparnis: Das manuelle Extrahieren von Daten aus PDFs kann zeitaufwändig sein, insbesondere wenn Sie große Dokumente verarbeiten müssen. Durch die Automatisierung des Prozesses können Sie den Zeit- und Arbeitsaufwand für die Extraktion von Daten aus PDF-Dateien erheblich reduzieren und so Ihre Zeit für höherwertige Aufgaben nutzen.
Erhöhte Genauigkeit: Das manuelle Kopieren und Einfügen von PDF-Daten kann fehleranfällig sein, insbesondere wenn Sie große Mengen an Dokumenten verarbeiten müssen. Indem Sie den Prozess automatisieren, können Sie das Risiko von Fehlern ausschließen und sicherstellen, dass Ihre Daten korrekt und konsistent sind.
Verbesserte Produktivität: Die Automatisierung der PDF-Datenextraktion kann Ihnen helfen, Ihre Produktivität zu steigern, indem Sie Ihre Arbeitsabläufe rationalisieren und den Zeit- und Arbeitsaufwand für Routineaufgaben reduzieren. Auf diese Weise können Sie in kürzerer Zeit mehr erreichen, so dass Sie sich auf wichtigere Projekte und Ziele konzentrieren können.
Die automatisierte PDF-Datenextraktion kann in einer Reihe von Situationen besonders nützlich sein. Wenn Sie z.B. im Finanz- oder Rechnungswesen arbeiten, müssen Sie vielleicht regelmäßig Daten aus Hunderten oder Tausenden von Rechnungen oder Quittungen extrahieren. Die Automatisierung dieses Prozesses kann Ihnen helfen, Zeit zu sparen und Fehler zu reduzieren und so die Effizienz Ihrer Abläufe zu verbessern.
Wenn Sie im Marketing oder Vertrieb arbeiten, müssen Sie vielleicht Daten aus Kundenfeedbackformularen, Umfragen oder anderen Dokumenten extrahieren. Die Automatisierung dieses Prozesses kann Ihnen dabei helfen, diese Daten schneller und effektiver zu analysieren, so dass Sie Trends, Erkenntnisse und Verbesserungsmöglichkeiten erkennen können.
Die automatisierte PDF-Datenextraktion kann ein wertvolles Tool für alle sein, die regelmäßig Daten aus PDFs extrahieren müssen. Ganz gleich, ob Sie ein Kleinunternehmer, ein Freiberufler oder ein großes Unternehmen sind, die Automatisierung kann Ihnen helfen, Ihren Arbeitsablauf zu verbessern, Zeit zu sparen und bessere Ergebnisse zu erzielen.
Wie man automatisiert Daten aus PDF-Dateien extrahiert
Nachdem wir nun die Vorteile der automatisierten PDF-Datenextraktion kennengelernt haben, wollen wir uns ansehen, wie Sie diesen Prozess starten können. In diesem Abschnitt gehen wir Schritt für Schritt durch den Prozess der automatischen Datenextraktion aus einem PDF-Tool.
Methode 1: Verwenden Sie das PDFelement Automatic Data Extraction Tool
Wondershare PDFelement - PDF Editor Es ist ein beliebter PDF-Editor mit fortschrittlichen Funktionen, darunter ein Tool zur automatischen Datenextraktion. Mit diesem Tool können Sie Daten aus PDFs automatisch extrahieren. Dazu verwenden Sie anpassbare Vorlagen, die bestimmte Datentypen wie Namen, Adressen und Telefonnummern erkennen und extrahieren können.
 G2-Wertung: 4.5/5 |
G2-Wertung: 4.5/5 |  100 % Sicher |
100 % Sicher |
 G2-Wertung: 4.5/5 |100 % Sicher |
G2-Wertung: 4.5/5 |100 % Sicher |
Um das Tool zur automatischen Datenextraktion in PDFelement zu verwenden, gehen Sie wie folgt vor:
Daten aus PDF-Formularfeldern extrahieren
Dieses Verfahren ist geeignet, wenn die PDF-Datei ein ausfüllbares Formular ist.
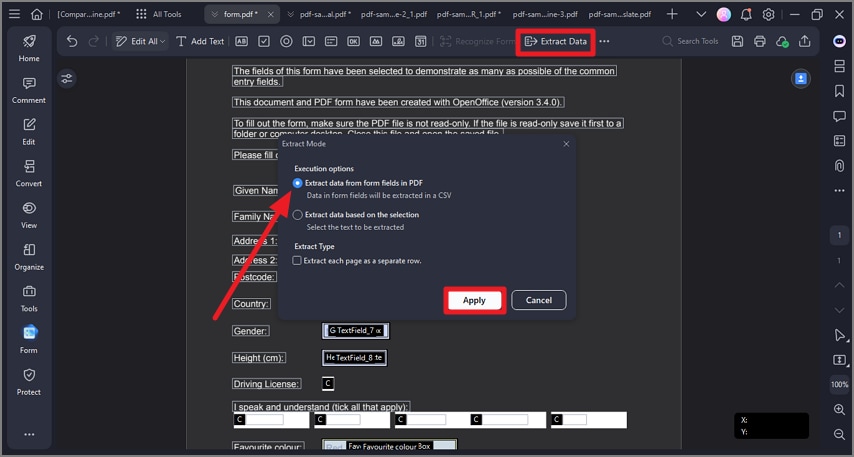
Schritt 1 Starten Sie PDFelement und klicken Sie auf "Formular".
Schritt 2 Klicken Sie auf die Option "Daten extrahieren".
Schritt 3 Wählen Sie "Daten aus Formularfeldern in PDF extrahieren".
Schritt 4 Klicken Sie auf die "Anwenden" Schaltfläche.
Daten aus ausgewählten PDF-Tests extrahieren
Wenn es sich bei Ihrer PDF-Datei nicht um ein ausfüllbares Formular handelt, können Sie Daten aus den markierten Bereichen der PDF-Datei extrahieren.
G2-Wertung: 4.5/5 | 100 % Sicher |
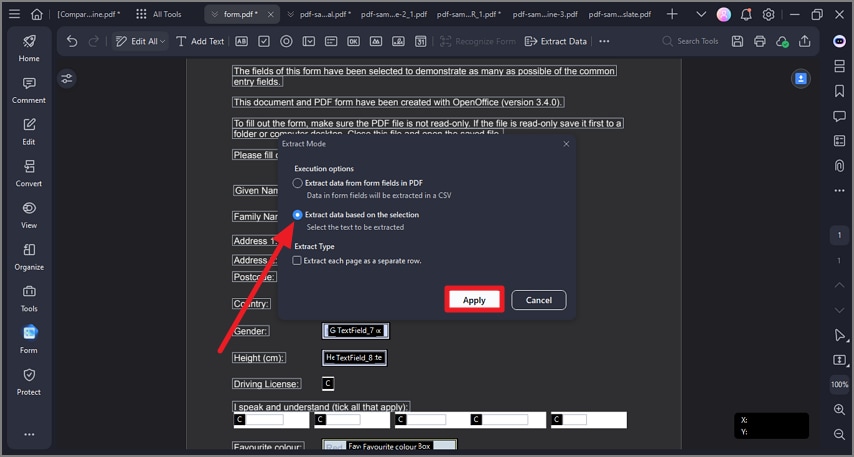
G2-Wertung: 4.5/5 |100 % Sicher |Schritt 1 Starten Sie PDFelement und klicken Sie auf "Formular" > "Daten extrahieren" > "Daten basierend auf der Auswahl extrahieren" > "Anwenden".
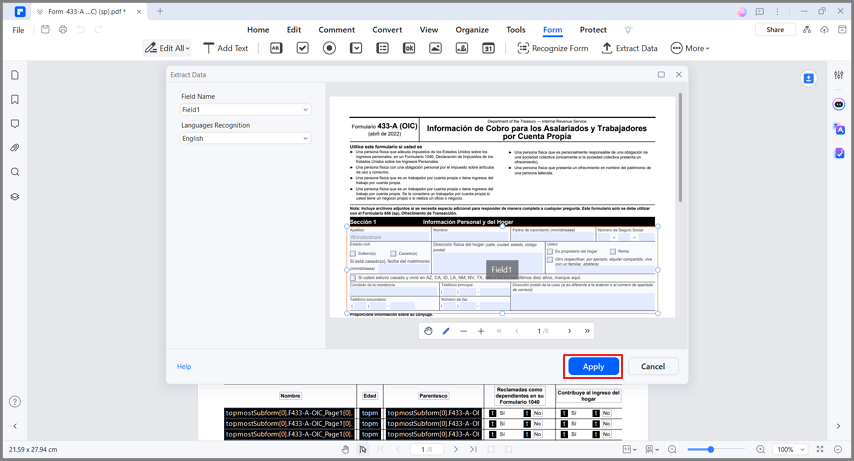
Schritt 2 Wählen Sie den Bereich auf der Seite aus, den Sie extrahieren möchten. Stellen Sie die Sprache auf der Registerkarte "Spracherkennung" ein und klicken Sie auf "Übernehmen".
Daten für Stapelverarbeitung extrahieren
Sie können das Stapelverarbeitungs-Tool verwenden, wenn Sie mehrere PDFs haben, aus denen Sie die Daten extrahieren möchten.
G2-Wertung: 4.5/5 | 100 % Sicher |
G2-Wertung: 4.5/5 |100 % Sicher |Schritt 1 Starten Sie PDFelement und klicken Sie auf "Tool" > "Stapelverarbeitung" > "Daten extrahieren".
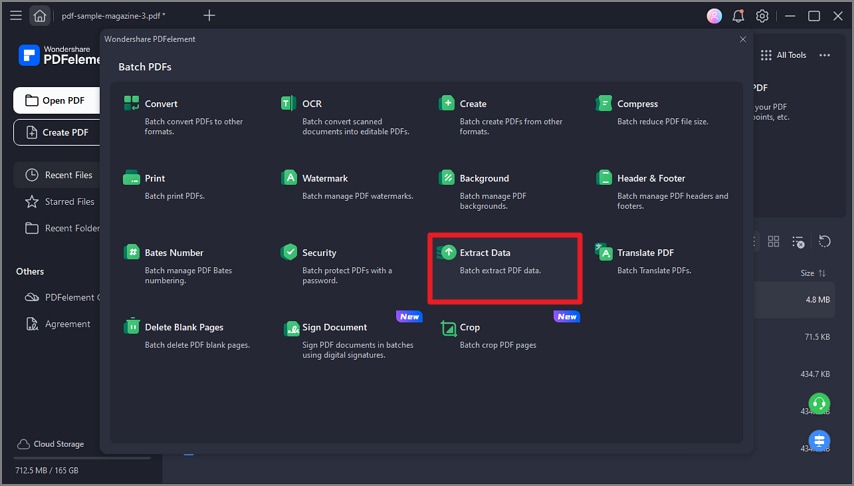
Schritt 2 Importieren Sie die PDFs und wählen Sie den Speicherort für die extrahierte Datei. Klicken Sie auf die "Übernehmen" Schaltfläche, um die Daten zu extrahieren.
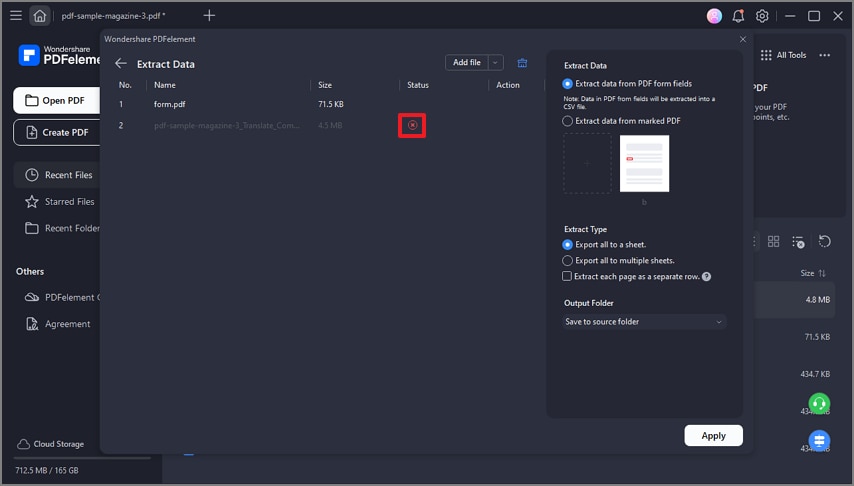
Sobald Sie Ihre Vorlage ausgewählt haben, scannt PDFelement das PDF-Dokument automatisch nach relevanten Daten und extrahiert diese in eine Tabellenkalkulation oder ein anderes Format, das Sie für weitere Analysen verwenden können. Sie können Ihre Vorlage auch anpassen, um bestimmte Daten oder Informationen aus Ihren PDF-Dokumenten zu extrahieren, was diese Methode äußerst flexibel und anpassbar macht.
Diese Methode kann besonders nützlich sein, wenn Sie Daten aus großen Mengen von PDF-Dokumenten extrahieren, z.B. Finanzberichte, Rechnungen oder Kundenfeedback-Formulare. Durch die Automatisierung der Datenextraktion können Sie den Zeit- und Arbeitsaufwand für die Extraktion von Daten aus diesen Dokumenten erheblich reduzieren und gleichzeitig die Genauigkeit und Konsistenz Ihrer Daten verbessern.
Methode 2: PDF in Excel konvertieren mit PDFelement
Die Konvertierung von PDF in Excel ist eine weitere leistungsstarke Methode zur Extraktion von Daten aus PDF-Dokumenten. Bei dieser Methode wird Ihre PDF-Datei mit PDFelement in eine Excel-Tabelle konvertiert, die mit den fortschrittlichen Datenverarbeitungstools von Excel leicht bearbeitet und analysiert werden kann.
Wie man das macht, erfahren Sie hier:
G2-Wertung: 4.5/5 | 100 % Sicher |
G2-Wertung: 4.5/5 |100 % Sicher |Schritt 1 Starten Sie PDFelement und importieren Sie die PDF-Datei.
Schritt 2 Klicken Sie auf "Konvertieren" > "Nach Excel".
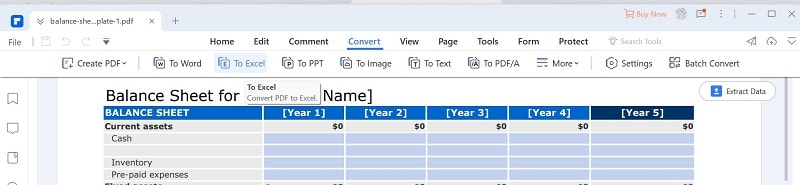
Schritt 3 Speichern Sie die Excel-Datei. Die PDF-Datei wird in Excel konvertiert. Geben Sie anschließend einen Zielordner an, in dem Sie die resultierende Excel-Datei speichern möchten.
Der Hauptvorteil der Konvertierung von PDF in Excel zur Datenextraktion ist die Flexibilität. Mit Excel können Sie Ihre Daten in einer Weise sortieren, filtern und analysieren, die mit einem PDF-Dokument nicht möglich ist. Darüber hinaus können Sie mit Excel Grafiken und Diagramme erstellen, um Ihre Daten zu visualisieren, so dass Sie Trends und Muster leichter erkennen können.
Diese Methode kann besonders nützlich sein, wenn Sie Daten aus Tabellen oder anderen strukturierten Daten innerhalb eines PDF-Dokuments extrahieren. Nehmen wir zum Beispiel an, Sie haben einen großen Finanzbericht, der mehrere Tabellen enthält. Durch die Konvertierung der PDF-Datei in Excel können Sie die Daten in jeder einzelnen Tabelle problemlos extrahieren und analysieren.
Eine weitere Situation, in der die Konvertierung von PDF in Excel nützlich sein kann, ist die Kombination von Daten aus mehreren PDF-Dokumenten in einer einzigen Tabellenkalkulation. Indem Sie jedes PDF in Excel konvertieren und die daraus resultierenden Tabellenblätter zusammenführen, können Sie Ihre Daten schnell und einfach für weitere Analysen konsolidieren.
Methode 3: Codes und Skripte verwenden
Die Verwendung von Codes und Skripten für die automatisierte PDF-Datenextraktion ist eine sehr anpassbare und flexible Methode, mit der Sie Daten aus PDF-Dokumenten mithilfe von Programmiersprachen wie Python, Java oder Ruby extrahieren können. Diese Methode bietet mehrere Vorteile, u.a. die Möglichkeit, große Datenmengen zu verarbeiten und den Extraktionsprozess an Ihre speziellen Anforderungen anzupassen.
Die grundlegenden Schritte für die Verwendung von Code und Skript zur automatischen Extraktion von Daten aus PDF-Dokumenten umfassen die Verwendung einer PDF-Bibliothek oder eines Moduls zum Lesen des PDF-Dokuments und zur Extraktion der relevanten Daten. Sie können zum Beispiel die PyPDF2-Bibliothek in Python verwenden, um Text und Daten aus PDF-Dokumenten zu extrahieren. Hier ist ein Beispiel-Codeausschnitt, der zeigt, wie Sie mit PyPDF2 Daten aus einem PDF-Dokument extrahieren können:
import PyPDF2
pdf_file = open('example.pdf', 'rb')
pdf_reader = PyPDF2.PdfFileReader(pdf_file)
page = pdf_reader.getPage(0)
text = page.extractText()
print(text)
In diesem Beispiel öffnen wir ein PDF-Dokument namens "example.pdf" und verwenden PyPDF2, um den Text der ersten Seite des Dokuments zu extrahieren. Wir können diesen Text dann bearbeiten, um die spezifischen Daten zu extrahieren, an denen wir interessiert sind.
Diese Methode kann besonders nützlich sein, wenn Sie Daten aus komplexen oder nicht standardisierten PDF-Dokumenten extrahieren müssen oder wenn Sie große Mengen von PDFs automatisch verarbeiten müssen. Nehmen wir an, Sie sind ein Datenanalyst, der mit Finanzberichten oder Rechnungen arbeitet. In diesem Fall können Sie Code und Skripte verwenden, um bestimmte Datentypen aus diesen Dokumenten automatisch zu extrahieren und so viel Zeit und Mühe zu sparen.
Vergleich der Methoden
Für die Automatisierung der PDF-Datenextraktion gibt es mehrere Methoden, die jeweils Vor- und Nachteile haben. Hier finden Sie eine Vergleichstabelle, die die wichtigsten Funktionen der einzelnen Methoden hervorhebt:
Methode |
Vorteile |
Nachteile |
| PDFelement Automatische Datenextraktion | Einfach zu bedienen, keine Programmierkenntnisse erforderlich | Eingeschränkte Flexibilität, möglicherweise nicht für alle PDF-Dokumente geeignet |
| PDF in Excel konvertieren mit PDFelement | Bietet Flexibilität und fortschrittliche Tools zur Datenverarbeitung | Funktioniert möglicherweise nicht bei allen PDF-Dokumenten, erfordert einige Excel-Kenntnisse |
| Code & Skripte verwenden | Hochgradig anpassbar, kann große Mengen an Daten verarbeiten | Erfordert Programmierkenntnisse, die Einrichtung kann zeitaufwändig sein |
Wie Sie sehen, hat jede Methode ihre Stärken und Schwächen. Welche Methode für Sie am besten geeignet ist, hängt von Ihren spezifischen Bedürfnissen und Ihrem Fachwissen ab. Wenn Sie nach einer einfachen, benutzerfreundlichen Lösung suchen, ist die automatische Datenextraktion von PDFelement vielleicht die beste Wahl für Sie. Wenn Sie jedoch mehr Flexibilität und fortgeschrittene Tools zur Datenverarbeitung benötigen, ist die Konvertierung von PDF in Excel mit PDFelement möglicherweise besser geeignet.
Wenn Sie über Programmierkenntnisse verfügen und große Datenmengen verarbeiten müssen, ist die Verwendung von Code und Skripten möglicherweise die effektivste Methode. Diese Methode erfordert jedoch mehr Einrichtungszeit und Fachwissen als die anderen Methoden, so dass es für manche eine bessere Wahl geben könnte.
Fazit
Die Automatisierung der PDF-Datenextraktion kann Ihnen Zeit sparen und die Genauigkeit Ihrer Datenanalyse erhöhen. Unter den vorgestellten Methoden ist PDFelement ein leistungsstarkes Tool zur automatischen Datenextraktion und -konvertierung. Mit seiner benutzerfreundlichen Oberfläche und den fortschrittlichen Tools zur Datenverarbeitung kann PDFelement Ihnen helfen, Ihren Arbeitsablauf zu rationalisieren und Ihre Produktivität zu steigern.
