Umwandlung einer Bild-PDF in eine durchsuchbare PDF-Datei
Lesen Sie den Artikel, um zu erfahren, wie Sie eine Bild-PDF-Datei in eine durchsuchbare PDF-Datei konvertieren.

2025-03-21 14:12:34 • Abgelegt unter: Mac How-Tos • Bewährte Lösungen
OCR oder Optical Character Recognition (optische Zeichenerkennung) ist der Prozess der Identifizierung von Text und anderen Zeichen in einer bildbasierten Datei und deren Umwandlung in eine Form, die entweder maschinell bearbeitet oder elektronisch durchsucht werden kann. OCR, auch bekannt als Texterkennung, ist ein sehr wertvolles kommerzielles Tool. Unternehmen nutzen es, um wichtige Dokumente zu digitalisieren und zu archivieren; Schulen verwenden es, um physische Inhalte in digitale Inhalte umzuwandeln; auch Privatpersonen können OCR nutzen, um ihre Quittungen, Rechnungen und andere Dokumente in elektronische Formate für verschiedene Zwecke wie die Online-Steuererklärung, etc. umzuwandeln.
Teil 1. Überblick über OCR
Die Vielseitigkeit von OCR
- OCR ist in mehreren Sprachen verfügbar. Zum Beispiel unterstützt Wondershare Wondershare PDFelement - PDF Editor Pro jetzt über 20 verschiedene Sprachen und kann sogar zweisprachige oder mehrsprachige Texte in editierbare und durchsuchbare PDF-Dateien umwandeln.
- Sie können auch den Seitenbereich auswählen, den Sie konvertieren möchten, falls Sie nicht das gesamte Dokument mit OCR bearbeiten möchten.
- Darüber hinaus haben Sie die Wahl, die Sprache entweder selbst festzulegen oder die Software diese erkennen zu lassen (falls der Text mehr als eine Sprache enthält).
 G2-Wertung: 4.5/5 |
G2-Wertung: 4.5/5 |  100 % Sicher |
100 % Sicher |
 G2-Wertung: 4.5/5 |100 % Sicher |
G2-Wertung: 4.5/5 |100 % Sicher |Wie man OCR-Ergebnisse verbessert
Da OCR nicht immer und unter allen Bedingungen 100 % genau ist, sollten Sie einige allgemeine Regeln beachten, bevor Sie eine gescannte PDF-Datei oder eine Bilddatei mit Text OCR-erfassen:
Muss für das menschliche Auge lesbar sein - Wenn Sie das Dokument deutlich lesen können, erhalten Sie viel bessere OCR-Ergebnisse. Dokumente, die von zerknittertem Papier gescannt wurden oder Bilder, die unscharf sind, liefern schlechte Ergebnisse.
Sie müssen eine mittlere oder hohe Auflösung haben - Text mit einer schlechten Auflösung führt zu schlechten OCR-Ergebnissen; stellen Sie also sicher, dass die verwendeten Bilder die richtige Auflösung haben. Sie können ein Tool zur Bildextrapolation verwenden, um die Auflösung oder die dpi zu erhöhen, damit Sie bessere Chancen auf genaue OCR-Ergebnisse haben.
Das Dokument entrauschen - Wenn der Text von anderen bedeutungslosen Zeichen begleitet wird, ist es für die OCR-Engine schwieriger, die tatsächlichen Zeichen von den zufälligen Formen zu trennen. Verwenden Sie einen Denoiser, um das Bildrauschen zu reduzieren und den Kontrast des Textes zu erhöhen und Sie erhalten genauere Konvertierungen.
Horizontaler Text ist besser als geneigter Text - OCR-Engines arbeiten, indem sie das Dokument horizontal von oben nach unten analysieren. Wenn der Text schräg oder geneigt ist, ist er schwieriger zu konvertieren. Stellen Sie daher sicher, dass Sie den Text nicht schräg stellen, bevor Sie ihn mit OCR bearbeiten.
Erweiterte OCR arbeitet mit mehr als nur Zeichen
Einfache OCR-Programme sind für die Bearbeitung einfacher Textinhalte konzipiert. Die fortschrittlicheren, wie das OCR-Plugin in PDFelement Pro, können jedoch Sonderzeichen, mathematische Operationen, chemische Formeln und verschiedene andere Zeichen erkennen. Die Sprachfunktion ist ein gutes Beispiel dafür, wie flexibel und leistungsstark sie ist. Wenn Sie ein Dokument mit einer Mischung aus Text, Sonderzeichen, Formeln und anderen seltsamen Informationen haben, die in bearbeitbare oder durchsuchbare PDF-Dateien umgewandelt werden können, ist PDFelement Pro die beste Option für Sie, um OCR zu verwenden.
Teil 2. Umwandlung einer Bild-PDF in eine durchsuchbare PDF-Datei
Die OCR eines Dokuments in PDFelement ist aufgrund des intelligenten Codes, der der intuitiven Benutzeroberfläche der Software zugrunde liegt, ein sehr einfacher Prozess. Wenn Sie eine PDF-Datei öffnen, die von einem physischen Dokument gescannt wurde oder ein Bild mit Text, das in PDF konvertiert wurde, erkennt die Software dies automatisch und fragt Sie, ob Sie zuerst das OCR-Plugin herunterladen und installieren möchten. Anschließend werden Sie aufgefordert, das Plugin zu installieren und die OCR-Aktion durchzuführen. Sehen wir uns nun Schritt für Schritt an, wie man das macht:
G2-Wertung: 4.5/5 | 100 % Sicher |
G2-Wertung: 4.5/5 |100 % Sicher |1. Um das Plugin manuell zu installieren, gehen Sie zu Tools → OCR Texterkennung oder zu PDFelement → Einstellungen → Plugin → Installieren.
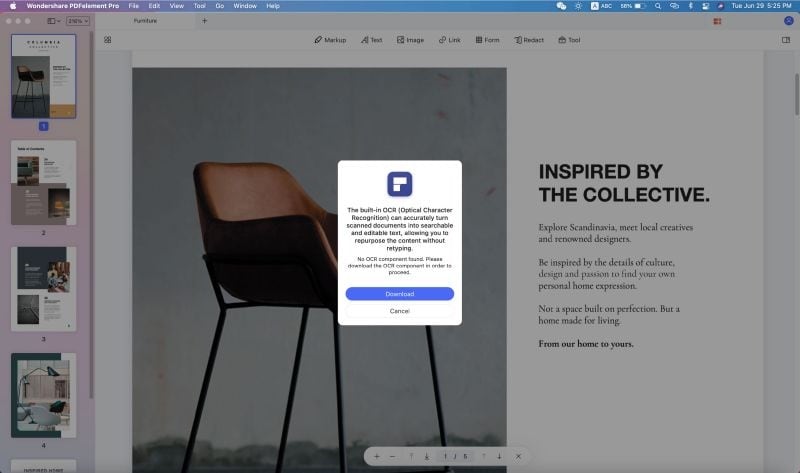
2. Wenn Sie eine nicht bearbeitbare PDF-Datei öffnen, sehen Sie eine Benachrichtigungsleiste und die Aufforderung "OCR durchführen" oberhalb der Dokumentansicht. Klicken Sie darauf.
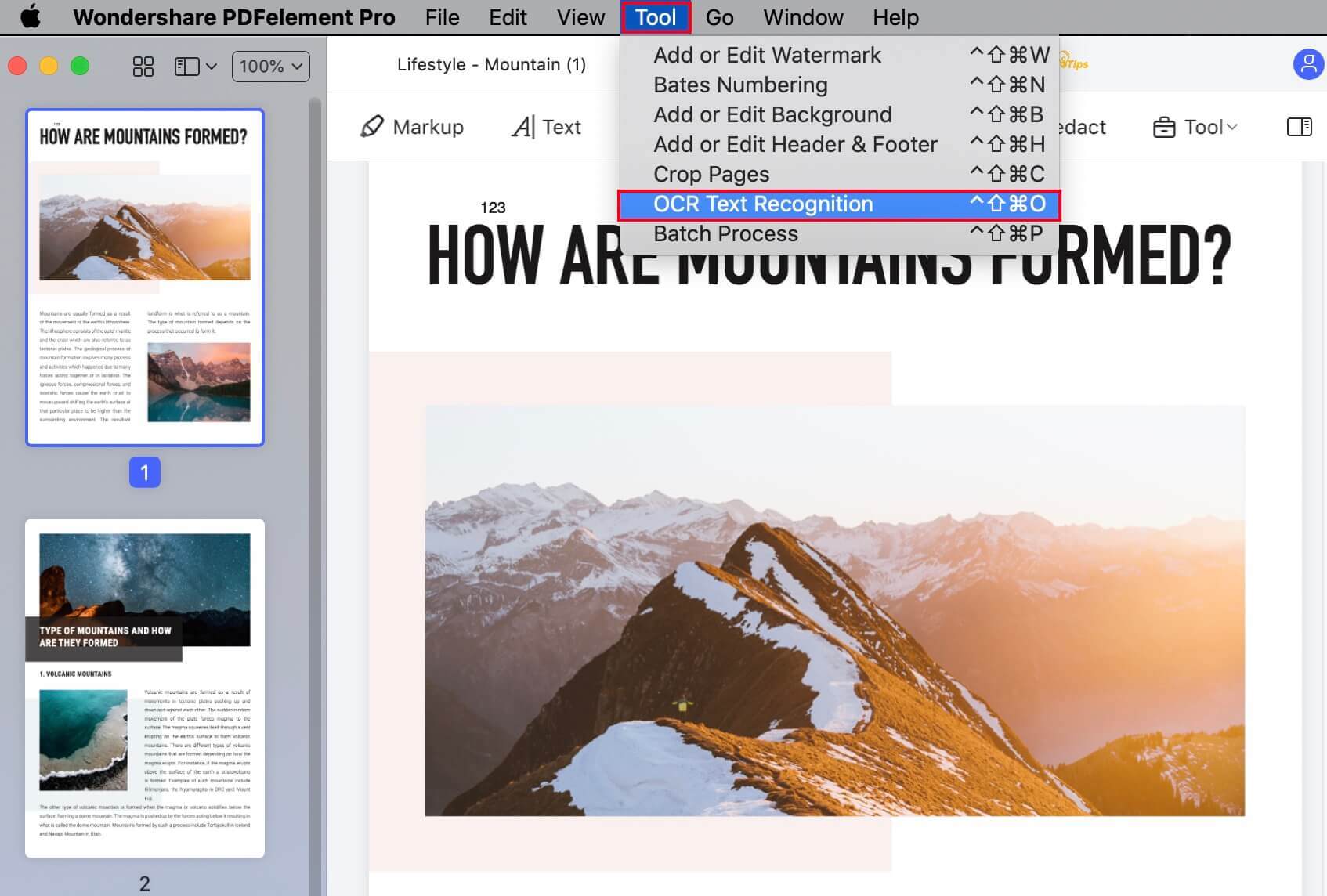
3. Wählen Sie in dem kleinen Pop-up-Fenster den zu konvertierenden Seitenbereich aus. Die Optionen sind Alle, Ungerade Seiten, Gerade Seiten und Benutzerdefiniert, was Ihnen die Flexibilität gibt, genau das zu wählen, was Sie wollen. Klicken Sie auf Ok, um fortzufahren.
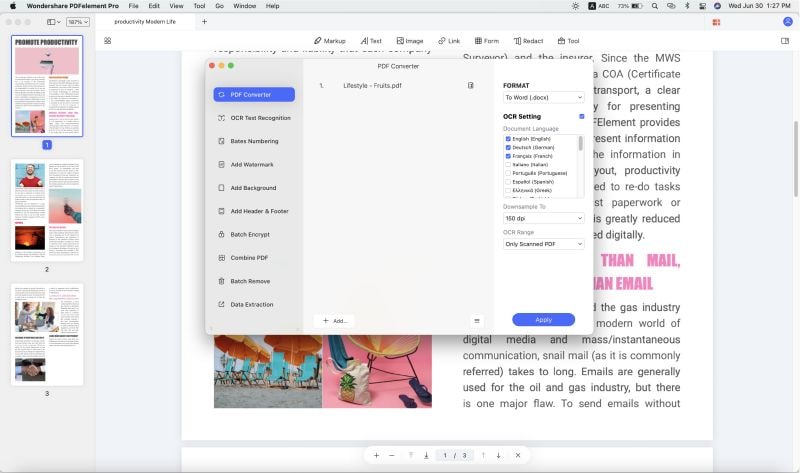
4. Wählen Sie im Fenster OCR-Einstellungen die Sprache, die Auflösung für das Downsampling und ob der konvertierte Text bearbeitbar oder nur durchsuchbar sein soll.
5. Klicken Sie auf OCR durchführen. Die Datei wird konvertiert und in der Software angezeigt. Sie können die Datei nun bearbeiten oder durchsuchen, je nachdem, welche Option Sie im vorherigen Schritt gewählt haben.
Wenn Sie mehr als ein Dokument mit OCR bearbeiten möchten, können Sie den OCR-Stapelprozess dafür verwenden.
1. Gehen Sie zu Tool → Stapel Prozess.
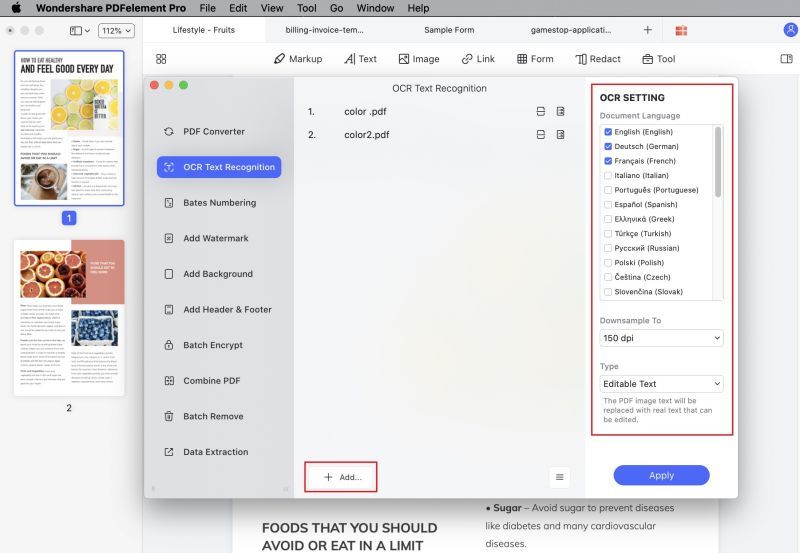
2. Wählen Sie im Fenster Stapelverarbeitung die Registerkarte OCR in der linken Seitenleiste.
3. Ziehen Sie nun Ihre Dateien per Drag & Drop oder verwenden Sie die Schaltfläche Dateien hinzufügen am unteren Rand, um mehrere gescannte Dokumente zu importieren.
4. Wählen Sie in der rechten Seitenleiste die OCR-Einstellungen wie oben beschrieben.
5. Klicken Sie auf Anwenden, um OCR für alle diese Dokumente durchzuführen.
Nach der Konvertierung können Sie Ihr(e) Dokument(e) unter einem anderen Dateinamen speichern, um anzugeben, ob sie bearbeitbar oder durchsuchbar sind. Die Originaldateien bleiben unverändert.
Teil 3. Woran erkennt man, dass eine PDF-Datei nicht zugänglich ist (bearbeitbar oder durchsuchbar)?
Wenn Sie eine PDF-Datei in PDFelement öffnen, scannt das Programm das Dokument automatisch und bereitet es für die Bearbeitung und andere Aufgaben vor. Wenn dies der Fall ist, erkennt es normalerweise den gescannten Text und warnt Sie mit der oben erwähnten Benachrichtigung. Falls Sie das übersehen, können Sie leicht feststellen, ob das Dokument zugänglich ist oder nicht.
G2-Wertung: 4.5/5 | 100 % Sicher |
G2-Wertung: 4.5/5 |100 % Sicher |1. Versuchen Sie, einen Text zu bearbeiten, indem Sie in der linken Seitenleiste auf Text klicken und einen beliebigen Text im Dokument auswählen. Wenn Sie ihn nicht auswählen können, bedeutet das, dass der Text nicht bearbeitet werden kann.
2. Versuchen Sie anschließend, mit dem Befehl Cmd+F nach Text zu suchen, den Sie im Dokument sehen können.
3. Versuchen Sie nun, die Bildbearbeitungsfunktion zu nutzen, indem Sie links auf Bild klicken und ein Bild auswählen.
Wenn Sie eine der oben genannten Aktionen nicht durchführen können, bedeutet dies, dass die PDF-Datei nicht lesbar, bearbeitbar oder durchsuchbar ist.
Teil 4. Was sind die Vorteile barrierefreier PDFs?
Wir alle wissen, dass OCR wichtig ist. Aber warum ist das der Fall? Warum können wir bildbasierte PDFs und gescannte PDFs nicht so belassen, wie sie sind? Die Gründe dafür sind vielfältig:
- Diese Dateien sind nicht leicht nach bestimmten Inhalten zu durchsuchen, was bei sehr großen Dateien zu einem Problem wird.
- Sie können nicht in andere bearbeitbare Formate wie Word, Excel, etc. umgewandelt werden.
- Wenn also die darin enthaltenen Informationen veraltet und irrelevant werden, wird die Datei selbst nutzlos, es sei denn, es gibt eine Möglichkeit, die Informationen zu aktualisieren.
- Bilder können nicht einzeln aus einer solchen Datei extrahiert werden, es sei denn, Sie verwenden eine Umgehungslösung, wie z.B. das Anfertigen von Screenshots. Wenn Sie ein Designer sind, wissen Sie, dass dies nicht die ideale Arbeitsweise ist.
Es gibt noch weitere Gründe, warum OCR ein wichtiger Bestandteil von Dokumenten-Workflows ist. Barrierefreie PDF-Dateien lassen sich leichter archivieren, durchsuchen, bearbeiten, konvertieren und für verschiedene andere Aufgaben nutzen, die mit einer nicht lesbaren Datei nicht möglich sind.
Teil 5. Warum PDFelement Pro zur OCR von PDFs
PDFelement Pro verwendet die leistungsstarke und präzise ABBYY® FineReader® Engine 11, um bildbasierte Dateien in bearbeitbare PDFs zu konvertieren. Diese OCR-Engine gehört zu den am besten bewerteten Anwendungen in dieser Kategorie und ist bekannt für ihre Genauigkeit, Geschwindigkeit und Fähigkeit, große Datenmengen (Stapel-Prozess) in kurzer Zeit zu verarbeiten.
Darüber hinaus bietet PDFelement selbst eine hervorragende Oberfläche, um mit solchen Dateien vor und nach der Konvertierung zu arbeiten. Bevor sie mit OCR konvertiert werden, können sie durch Entfernen oder Hinzufügen von Seiten, Zusammenführen von Dateien, Entfernen von Wasserzeichen etc. organisiert werden. Sobald sie mit OCR konvertiert sind, können Sie mit PDFelement eine Vielzahl anderer Operationen durchführen, wie z.B. Konvertierung, Schutz, Ausfüllen von Formularen, elektronische Unterzeichnung, Optimierung der Dateigröße und verschiedene andere wichtige Aufgaben wie diese.
Vor allem aber ist PDFelement Pro eine der erschwinglichsten PDF-Lösungen auf dem Markt mit einer so beeindruckenden Bandbreite an Funktionen, einer intuitiven Benutzeroberfläche, einer bequemen Navigation, nützlichen Prozessen und einer Lernkurve, die praktisch gleich Null ist.
Frequently Asked Questions (FAQs)
Kann OCR handschriftlichen Text umwandeln?
Ja, solange die Handschrift lesbar und klar (nicht verblasst) ist und das Papier vor dem Scannen nicht zerknittert ist, kann OCR handschriftlichen Text recht gut lesen. Natürlich ist es nicht so genau wie OCR bei gedrucktem Text, aber bis zu einem gewissen Grad ist es durchaus möglich.
Kann ich direkt von einem Scanner eine bearbeitbare PDF-Datei erstellen?
Ja, PDFelement verfügt über eine Option Datei → Neu → PDF aus Scanner im Menü, die Sie für diese Funktion verwenden können. Sie müssen lediglich Ihren Scanner an denselben Computer anschließen, auf dem auch PDFelement Pro läuft, diesen Menüpunkt zum Auslösen des Prozesses verwenden und die angezeigten Schritte ausführen. Sie können das gescannte Dokument bearbeitbar oder durchsuchbar machen.
Kostet OCR mit PDFelement Pro extra?
Nein, das OCR-Plugin ist im Lieferumfang von PDFelement Pro enthalten. Es muss jedoch separat heruntergeladen und installiert werden (siehe oben). Das liegt daran, dass es sehr groß ist, was sich auf die Download- und Installationszeit für PDFelement selbst auswirkt, wenn es in der Installationsdatei enthalten war.
Kostenlos Downloaden oder PDFelement kaufen jetzt sofort!
Kostenlos Downloaden oder PDFelement kaufen jetzt sofort!
PDFelement kaufen jetzt sofort!
PDFelement kaufen jetzt sofort!

Noah Hofer
staff Editor