
PDFelement - Leistungsstarker und einfacher PDF-Editor
Starten Sie mit der einfachsten Art, PDFs zu verwalten - mit PDFelement!
PDF ist ein Akronym für Portable Document Format und gilt als das beste Format für die gemeinsame Nutzung elektronischer Dokumente. PDFs sind allgegenwärtig und für die Arbeitsabläufe in jedem Unternehmen unverzichtbar. PDF-Dateien enthalten alle Arten von Inhalten, einschließlich Tabellen. Bankangestellte müssen Kundeninformationen aus Tabellen extrahieren, Lehrer müssen Noten aus Tabellen extrahieren, um Zeugnisse zu erstellen und Buchhalter benötigen Tabellendaten, um Rechnungen und Belege zu erstellen.
Es gibt zwar mehrere Möglichkeiten, Tabellen aus PDF-Dateien zu extrahieren, aber Python erweist sich als eine hervorragende Methode. Python ist eine interaktive Computerprogrammiersprache, die für die Entwicklung von Webseiten und Software verwendet wird. Das Tool bietet jedoch auch eine Plattform zum Lesen und Extrahieren von Tabellen aus PDF-Dateien. Mit einem geeigneten Codeschnipsel können Sie die gewünschte Tabelle mit Python aus dem PDF extrahieren. Dieser Artikel zeigt Ihnen, wie Sie mit Python auf einfachste Weise eine Tabelle aus einer PDF-Datei extrahieren können.
Methode 1: Tabular-Py Python Wrapper zum Extrahieren von Tabellen aus PDF verwenden
Tabular-py ist ein Wrapper von Tabular Java - einer Java-Bibliothek, mit der Sie den Inhalt einer in ein PDF-Dokument eingebetteten Tabelle lesen können. Er liest die Tabelleninhalte und konvertiert sie in einen Pandas DataFrame. Mit tabula-py können Sie Ihre PDF-Datei in CSV-, TSV- oder JSON-Dateien umwandeln. Ihr System muss jedoch über Java8+ und Python 3.7+ verfügen. Sie sollten die folgenden Befehle ausführen, um die erforderlichen Java-Abhängigkeiten automatisch herunterzuladen und auf Ihrem System zu installieren.
$ pip install tabula-py
$ pip install tabulate
Angenommen, der Speicherpfad für die PDF-Datei mit der Zieltabelle lautet /home/Ubuntu/data.pdf. Sie können den folgenden Code im Terminal ausführen, um die Tabelle in Ihrer PDF-Datei zu extrahieren und als CSV, TSV oder JSON zu speichern.
Tabula importieren
# beginnen Sie mit dem Import der Tabula-Bibliothek
Tabula importieren
# Tabelle aus pdf-Datei lesen
dfs = tabula-read_pdf("/home/ubuntu/data.pdf",pages="all")
# Ihre PDF-Tabelle in das CSV-Format konvertieren
tabula.convert_into ("/home/ubuntu/data.pdf","output.csv","outpour_format="csv", pages="all")
Sie können die Tabelle auch mit folgendem Code aus dem Terminal extrahieren und drucken.
from tabula import read_pdf
from tabulate import tabulate
# Dieser Befehl liest die Tabelle in Ihrer PDF-Datei
df = read_pdf("/home/ubuntu/data.pdf",pages="all")
# Dieser Befehl druckt Ihre PDF-Datei im Terminal aus.
print(tabulate(df)
Der Befehl read_pdf () liest den Inhalt der Tabelle in Ihrer PDF-Datei.
Der Befehl tabulate () ordnet die gelesenen Daten in einem Tabellenformat an.
Tipps und Hinweise
· Stellen Sie sicher, dass Java auf Ihrem System vorhanden ist.
· Versuchen Sie, Grundkenntnisse in Python zu haben, um Ihre Arbeit zu erleichtern.
Methode 2: Verwenden Sie die Camelot-Py Python-Bibliothek zum Extrahieren von Tabellen aus PDF-Dateien
Camelot ist eine weitere nützliche Python-Bibliothek, mit der Sie Tabellen aus PDF-Dateien extrahieren können. Das Schöne an Camelot ist der Grad der Kontrolle, den es bietet. Diese Bibliothek gibt Ihnen mehr Möglichkeiten, Ihre Tabellenextraktion anzupassen und Ihren Bedürfnissen gerecht zu werden. Außerdem ist jede Tabelle ein Pandas DatFrame, der sich leicht in ETL- und Datenanalyse-Workflows integrieren lässt. Mit der Camelot-Bibliothek können Sie Ihre Tabellen in eine Vielzahl von Dateiformaten exportieren, darunter JSON, Excel, HTML und Sqlite.
Um die Camelot-Bibliothek auf Ihrem System zu installieren, führen Sie den folgenden Befehl aus.
$ pip install camelot-py
Im Gegensatz zu tabula-py verwendet Camelot Arrays und Indizes, um auf eine bestimmte Tabelle in Ihrer PDF-Datei zuzugreifen. Die Tabelle wird zunächst mit der Funktion read_pdf () gelesen und die Tabellen in einem Array von Tabellen gespeichert. Die Arrays beginnen natürlich mit Tabellen [0], dann mit Tabellen [1] und so weiter. Um ein PDF im Terminal zu drucken, können Sie den folgenden Code ausführen.
camelot importieren
# Extrahieren Sie alle Tabellen aus der PDF-Datei.
abc = camelot.read_pdf("/home/ubuntu/data.pdf")
# die erste Tabelle als Pandas DataFrame ausgeben
print(abc[0].df)
Der Befehl "import Camelot" importiert die Camelot-Bibliothek zur Verwendung in Ihrem Programm. Wenn die Camelot-Bibliothek nicht installiert ist, wird Python stattdessen eine Fehlermeldung ausgeben.
Der Befehl Camelot.read_pdf () liest den Inhalt Ihrer PDF-Tabelle und speichert ihn in einem Array von Tabellen abc.
Der Befehl print (abc[0].df) gibt die erste Tabelle im Array, d.h. Tabelle [0], auf dem Terminal aus.
Tipps und Hinweise
· Verwenden Sie die Parsing-Funktion, um schlechte Tabellen auf der Grundlage von Genauigkeit und Leerzeichen zu verwerfen.
· Wenn Sie Tabellen von verschiedenen Seiten extrahieren und die Reihenfolge der Extraktion ändern möchten, können Sie den Befehl order innerhalb der Parsing-Funktion verwenden.
· Versuchen Sie, sich mit der Python-Syntax vertraut zu machen, um Konvertierungsprobleme zu minimieren.
[Bonus] PDFelement: Tabellen aus PDFs extrahieren - komfortabler als mit Python
Python ist zwar nützlich, um Tabellen aus PDFs zu extrahieren, bietet aber nicht den Komfort eines speziellen Tools zur Extraktion von PDF-Daten. Python ist eine Programmiersprache und es ist nicht einfach, die Syntax zu verstehen und auswendig zu lernen. Wenn Sie neu in Python sind, werden Sie vielleicht die erste Zeile lesen und entmutigt sein. Sie benötigen professionelle Kenntnisse, um einfach und präzise zu navigieren und Tabellen aus PDF-Dateien zu extrahieren. Selbst wenn Sie ein Profi sind, ist das Schreiben und Ausführen von Codes zum Extrahieren von Tabellendaten zeitaufwändig und lästig.
Glücklicherweise löst PDFelement dieses Problem, indem es Ihnen eine bequeme Plattform zum Extrahieren von Tabellen aus PDF-Dateien bietet. Die Oberfläche ist elegant und einfach zu bedienen. Wenn Sie ein Neuling sind, werden Sie das Navigieren und Extrahieren von Tabellen aus PDF-Dateien als äußerst einfach empfinden. Sie benötigen keine Programmierkenntnisse oder Erfahrung, um mit dieser Software Tabellen in PDF-Dateien zu extrahieren. Außerdem ist Wondershare PDFelement mit verschiedenen Geräten und Betriebssystemen kompatibel, darunter Windows, Mac und iOS. Sie müssen sich keine Gedanken über das Hinzufügen von Bibliotheken machen, denn dieses Programm ist vollgepackt. Auch hier gilt: Die erstaunliche Verarbeitungsgeschwindigkeit und der günstige Preis machen es zu einem praktischen Tool für alle Benutzer, auch für Amateure.
Methode 1: Extrahieren von Tabellen unter Beibehaltung des Originalformats
Manchmal möchten Sie Tabellen aus PDF-Dateien extrahieren, ohne das Originalformat zu verändern. Dies ist nützlich, wenn Sie sowohl die Tabelle als auch den Inhalt benötigen, wenn Sie die Tabelle in genau demselben Format darstellen möchten oder wenn Sie nicht daran interessiert sind, das Layout der Tabelle zu verändern. Dieser Vorgang ist in PDFelement schnell und einfach, wie unten dargestellt.
Schritt 1 Starten Sie zunächst PDFelement auf Ihrem Gerät und laden Sie die Datei hoch, aus der Sie Tabellen extrahieren möchten. Alternativ können Sie auch mit der rechten Maustaste auf die PDF-Datei klicken und sie mit Wondershare PDFelement öffnen.
Schritt 2 Wenn die PDF-Datei geladen ist, gehen Sie zur Symbolleiste und klicken Sie auf die Registerkarte "Konvertieren". Wählen Sie aus den darunter angezeigten Optionen die Option "Nach Excel".
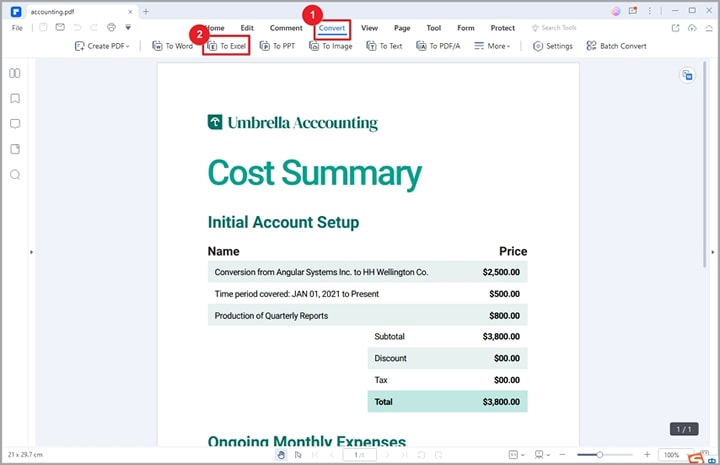
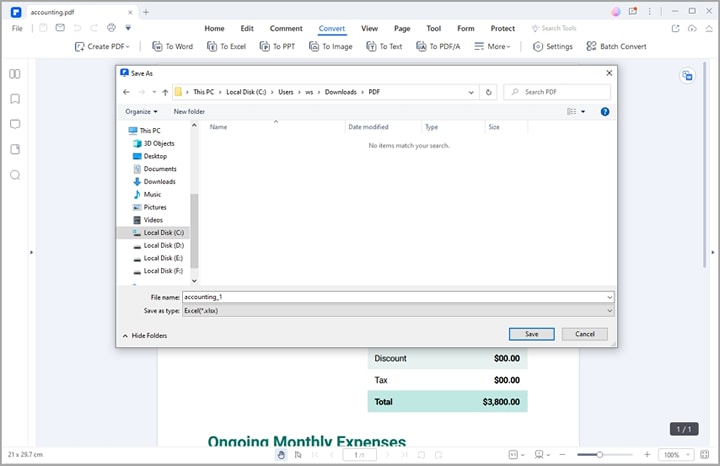
Schritt 3 PDFelement führt Sie automatisch zum Ausgabefenster "Speichern unter". Wählen Sie hier einen geeigneten Zielordner und klicken Sie auf die "Speichern" Schaltfläche. PDFelement wird Ihre PDF-Datei sofort in eine Excel-Datei umwandeln. Öffnen Sie die Excel-Datei, um die Tabelle zu überprüfen.
Tipps und Hinweise
· Wenn Sie mehrere Dateien bearbeiten, verwenden Sie den Stapelprozess, um Zeit und Energie zu sparen.
· Wenn Sie eine mehrseitige Datei haben und nur einen Teil davon benötigen, schneiden Sie sie einfach vor der Konvertierung von PDF in Excel zu.
Methode 2: Nur Daten aus PDF in CSV extrahieren
In anderen Fällen geht es Ihnen nicht um das Tabellenformat, sondern um den Inhalt der Tabelle. In diesem Szenario müssen Sie nur den Inhalt der PDF-Tabelle extrahieren. Glücklicherweise können Sie mit PDFelement nur Daten aus PDF-Dateien in CSV-Dateien extrahieren. CSV ist ein einfaches Textformat, das Daten in tabellarischer Form mit Kommas organisiert.
 G2-Wertung: 4.5/5 |
G2-Wertung: 4.5/5 |  100 % Sicher |
100 % Sicher |
 G2-Wertung: 4.5/5 |100 % Sicher |
G2-Wertung: 4.5/5 |100 % Sicher |Wondershare PDFelement - PDF Editor ermöglicht es Ihnen, Daten aus einem ausfüllbaren PDF-Formular zu extrahieren. Das PDF-Formular muss jedoch ausfüllbare Formularfelder enthalten, bevor Sie die Daten der PDF-Tabelle in die CSV-Datei extrahieren können. Wenn die Formularfelder nicht ausfüllbar/erkennbar sind, benötigen Sie die PDFelement OCR-Funktion, um sie erkennbar/ausfüllbar zu machen. Die Schritte sind unten abgebildet.
Schritt 1 Öffnen Sie Ihre PDF-Datei mit PDFelement. Stellen Sie sicher, dass in Ihrer PDFelement-Version das OCR-Plugin installiert ist.
Schritt 2 Gehen Sie zum Abschnitt "Formular" und klicken Sie auf das "Erkennen" Symbol aus den verschiedenen darunter angezeigten Optionen. PDFelement macht Ihre PDF-Formularfelder automatisch wiedererkennbar.
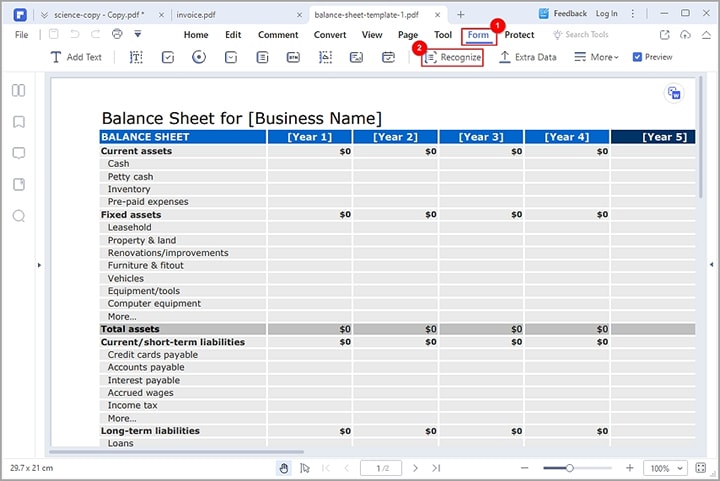
Da die PDF-Datei nun erkennbar ist, müssen Sie wie folgt vorgehen, um Tabellendaten aus Ihrer PDF-Datei zu extrahieren.
Schritt 1 Gehen Sie zur Symbolleiste und klicken Sie auf die Registerkarte "Formular". Klicken Sie unter den angezeigten Optionen auf die Option "Daten extrahieren".
Schritt 2 PDFelement zeigt das Dialogfenster "Daten extrahieren" auf dem Bildschirm an. Hier können Sie entweder "Daten aus Formularfeldern extrahieren" oder "Daten basierend auf der Auswahl extrahieren" wählen. Wenn Sie die Option "Daten aus Formularfeldern extrahieren" wählen, werden Ihre Formularfelder in eine CSV-Datei extrahiert.
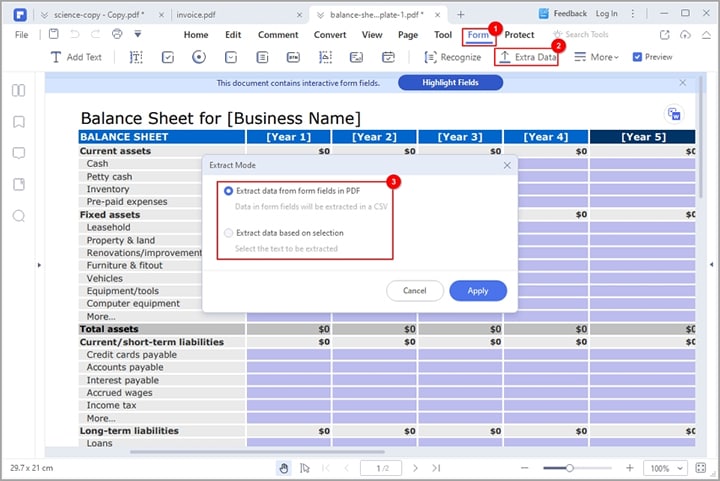
Wenn Sie die Option "Daten auf Basis der Auswahl extrahieren" wählen, müssen Sie jedes Formularfeld, das extrahiert werden soll, mit dem Cursor im Popup-Dialog auswählen. Danach geben Sie den Namen der ausgewählten Formularfelder ein und wählen eine geeignete Erkennungssprache.
Schritt 3 Nachdem Sie alle gewünschten Formularfelder ausgewählt haben, klicken Sie auf die "Übernehmen" Schaltfläche. PDFelement extrahiert die Daten sofort nur aus PDF in CSV.
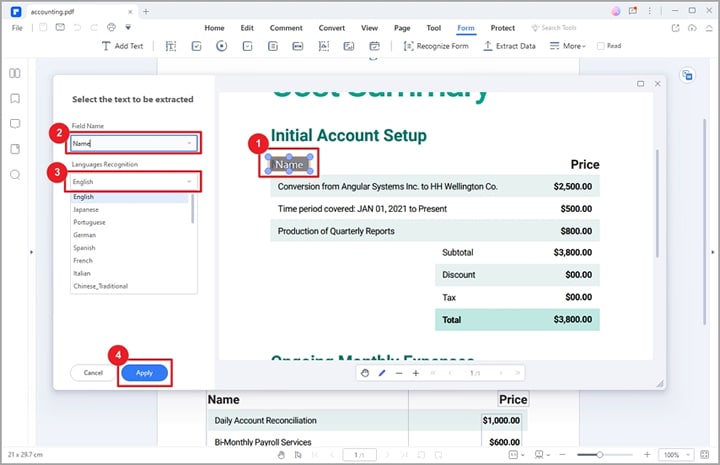
Tipps und Hinweise
· Wenn Sie Daten aus nicht ausfüllbaren Feldern extrahieren möchten, stellen Sie zunächst sicher, dass das OCR-Plugin für die PDF-Erkennung installiert ist.
· Verwenden Sie den Stapelprozess, wenn Sie mehrere PDFs haben, aus denen Sie Daten aus demselben Bereich extrahieren müssen oder wenn Sie Daten aus einem PDF-Formular mit mehreren Tabellen mit unterschiedlichen Daten extrahieren möchten.
· Die Funktion "Extrahieren von Daten anhand der Auswahl" kann sowohl auf textbasierte als auch auf gescannte PDF-Formulare angewendet werden.
· Da Sie jedes Formularfeld manuell auswählen müssen, verwenden Sie die Option "Daten auf der Grundlage der Auswahl extrahieren", wenn Sie nur eine kleine Datenmenge benötigen.
Das Extrahieren von Tabellen aus PDF-Dateien mit Python erfordert Programmierkenntnisse und Fachwissen. PDFelement bringt Ihnen jedoch die PDF-Tabellenextraktion mit einer intuitiven und benutzerfreundlichen Oberfläche näher. Das Verfahren ist einfach und bequem für jeden Benutzer, auch für Neulinge. Laden Sie PDFelement noch heute herunter und genießen Sie ein unvergleichliches Erlebnis beim Extrahieren von Tabellen aus PDF-Dateien.
