Hin und wieder möchten Sie vielleicht gescannte PDF-Dokumente ändern oder bearbeiten, beispielsweise indem Sie die Größe von Schriftarten und Bildern ändern oder Text aus einem PDF-Bild auslesen. In diesem Artikel erkläre ich Ihnen die effizienteste Möglichkeit, wie Sie mithilfe von PDFelement Text aus PDF-Dateien und sogar aus PDF-Bildern extrahieren.
 100% sicher | Werbefrei | Keine Malware
100% sicher | Werbefrei | Keine MalwareUm diese Aufgaben erfolgreich zu erledigen, benötigen Sie den besten Text-Extraktor für PDF-Dateien, zum Beispiel PDFelement. Mit diesem Tool können Sie Text aus PDF-Dateien einfach extrahieren und OCR nutzen, um gescannte PDF-Dateien zu bearbeiten und so Text aus PDF-Bildern zu erhalten. Darüber hinaus arbeitet diese OCR-Funktion mehrsprachig. Sie kann über 20 weltweit verwendete Sprachen erkennen.
Lassen Sie uns nun einen Blick auf die erweiterten Funktionen der Software werfen:
- Konvertiert PDF in andere Formate wie Excel, Text, PowerPoint, Word, Bilder und weitere.
- Bearbeitet PDF-Inhalte wie Schriften, Seiten, Bilder, Texte und sogar Wasserzeichen.
- Erstellt PDF aus existierenden Dokumenten, HTML, bestehenden PDF-Dateien und Bildern usw.
- Unterstützt den Schutz Ihrer PDF-Dokumente durch die Nutzung von Passwörtern und das Einschränken der Zugriffsberechtigungen für Ihre Dokumente.
- Ermöglicht das Ausfüllen von PDF-Formularen, einschließlich gescannter PDF-Formulare. Wenn Sie noch keine PDF-Formulare nutzen, können Sie diese mit den integrierten Werkzeugen erstellen.
100% sicher | Werbefrei | Keine MalwareEinfache Schritte zum Extrahieren von Text aus PDF
Im Folgenden finden Sie die Schritte zum Extrahieren von Text aus PDF-Text mit PDFelement.
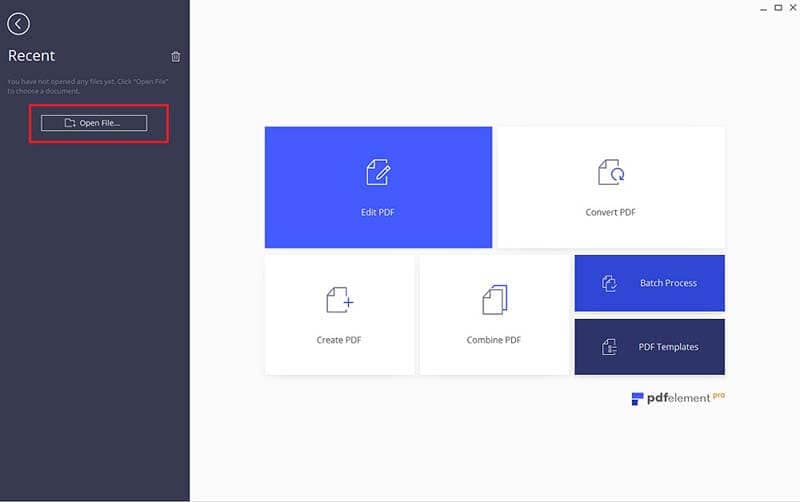
Schritt 1. PDF-Dateien zum Programm hinzufügen
Laden Sie PDFelement herunter und installieren Sie es. Öffnen Sie die zu extrahierenden PDF-Dateien und klicken Sie auf den Knopf „Datei öffnen“, um eine PDF-Datei hinzuzufügen.
Schritt 2. Text aus PDF extrahieren
Sobald die Datei geladen wurde, klicken Sie auf den „Bearbeiten“-Tab und anschließend auf den Knopf „Auswählen“. Nun können Sie mit der rechten Maustaste auf den Text klicken und „Text kopieren“ wählen, um den gewünschten Text zu extrahieren.
Wie Sie Text aus PDF-Bildern extrahieren
Schritt 1. Ihre bildbasierte PDF-Dateien öffnen
Nachdem Sie PDFelement installiert haben, können Sie es nun öffnen, um OCR auf Ihr PDF auszuführen. Starten Sie zunächst PDFelement und klicken Sie dann auf „Datei öffnen“, um die gescannte Datei in das Programm zu laden. Wählen Sie das gewünschte Bild-Dokument.
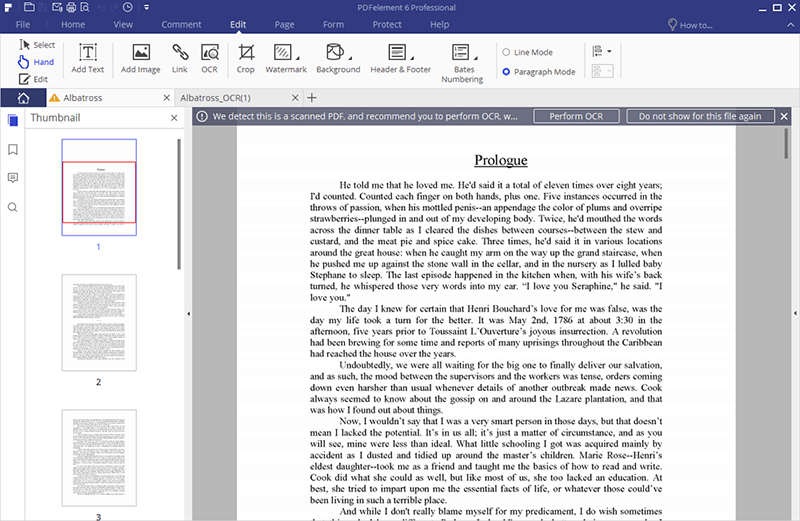
Schritt 2. OCR ausführen
Nachdem Sie die Datei geöffnet haben, erkennt das Programm, dass es sich dabei um ein gescanntes Dokument handelt und Sie daher OCR darauf anwenden müssen. Klicken Sie auf die Option „OCR ausführen“ in der oberen gelben Leiste. Wählen Sie dann eine OCR-Sprache und klicken Sie auf „OK“. Standardmäßig wird Englisch verwendet, Sie können die Option aber nach Belieben anpassen.
Schritt 3. Text aus einer Bild-PDF-Datei extrahieren
Sobald Sie OCR ausgeführt haben, können Sie den Text nun aus der PDF-Datei extrahieren. Gehen Sie dazu auf den „Bearbeiten“-Tab und dann auf den „Bearbeiten“-Knopf. Wählen Sie den gewünschten Text aus und führen Sie dann einen Rechtsklick aus, um die Kopie auszuwählen.
Alternativ können Sie Ihre PDF-Datei auch in das Word-Format konvertieren. Klicken Sie auf den „Zu Word“-Knopf auf dem „Startseite“-Tab. Klicken Sie im Dialogfenster den „Speichern“-Knopf, um Ihre PDF in das Word-Format zu konvertieren. Sie haben Ihr PDF-Dokument damit in einem editierbares Format konvertiert und können die Inhalte aus Ihrer soeben konvertierten Datei extrahieren.