
PDF Scraping ist das Extrahieren von Daten aus PDF-Dateien mit Hilfe automatisierter Tools. Mit der zunehmenden Menge an Daten, die in PDF-Dateien gespeichert sind, ist PDF Scraping zu einem wichtigen Tool für Unternehmen und Forscher geworden, die Daten schnell und genau erfassen und analysieren müssen. PDF Scraping kann Daten wie Text, Tabellen und Bilder aus PDF-Dateien extrahieren, die dann mit Datenanalyse-Tools analysiert werden können.
In PDF-Dateien werden häufig wichtige Daten gespeichert, z.B. Finanzberichte, Forschungsarbeiten und behördliche Dokumente. Mit PDF Scraping Tools können Forscher und Unternehmen schnell Daten aus diesen Dateien extrahieren und analysieren, um Erkenntnisse zu gewinnen und datengestützte Entscheidungen zu treffen. Dies macht PDF Scraping zu einem unverzichtbaren Tool für datengesteuerte Branchen und Forschungsbereiche.

In diesem Artikel
Vorteile von PDF Scraping
PDF Scraping bietet zahlreiche Vorteile für Unternehmen, Forscher und andere Fachleute, die Daten aus PDF-Dateien extrahieren müssen. Hier sind einige der wichtigsten Vorteile der Verwendung von PDF Scrapern:
- Produktivität: PDF Scraper können große Datenmengen in einem Bruchteil der Zeit extrahieren, die Sie benötigen würden, um dieselben Daten manuell zu extrahieren. Diese erhöhte Produktivität ermöglicht es Unternehmen und Forschern, sich auf die Analyse der Daten zu konzentrieren, anstatt Stunden mit deren Extraktion zu verbringen.
- Präzision: PDF Scraper verwenden fortschrittliche Algorithmen, um Daten genau zu extrahieren, wodurch das Risiko von Fehlern, die bei der manuellen Datenextraktion auftreten können, verringert wird. Dadurch wird sichergestellt, dass die extrahierten Daten zuverlässig und für datengestützte Entscheidungen unerlässlich sind.
- Kosteneffizienz: Durch die Automatisierung der Datenextraktion können PDF Scraper den mit der manuellen Datenextraktion verbundenen Zeit- und Kostenaufwand erheblich reduzieren. Dadurch können Unternehmen und Forscher Geld für Ressourcen und Personal sparen, die für die manuelle Datenextraktion benötigt werden.
- Flexibel: PDF Scraper können verschiedene Arten von Daten extrahieren, darunter Text, Tabellen und Bilder, so dass die Benutzer die spezifischen Daten extrahieren können, die sie für ihre Analyse benötigen. Dank dieser Flexibilität können die Benutzer die Datenextraktion an ihre Bedürfnisse anpassen.
- Benutzerfreundlichkeit: PDF Scraper sind benutzerfreundlich und erfordern nur minimale technische Kenntnisse, so dass sie für viele Benutzer zugänglich sind. Diese Benutzerfreundlichkeit reduziert die Lernkurve, die mit der manuellen Datenextraktion verbunden ist und macht den Prozess insgesamt effizienter.
- Kompatibilität: PDF Scraper können Daten aus verschiedenen Formaten und Versionen extrahieren, so dass sie mit vielen PDF-Dateien kompatibel sind. Diese Kompatibilität stellt sicher, dass die Benutzer Daten aus jeder PDF-Datei extrahieren können, die sie benötigen, unabhängig von deren Format oder Version.
PDFelement als PDF Scraper
PDFelement ist ein leistungsstarker PDF Editor und Converter, der Daten aus PDF-Dateien extrahieren kann und damit ein nützliches Tool für das PDF Scraping ist. Mit seinen fortschrittlichen Funktionen und seiner benutzerfreundlichen Oberfläche ist PDFelement eine hervorragende Option für Unternehmen und Forscher, die schnell und präzise Daten aus PDF-Dateien extrahieren müssen.
 G2-Wertung: 4.5/5 |
G2-Wertung: 4.5/5 |  100 % Sicher |
100 % Sicher |
 G2-Wertung: 4.5/5 |100 % Sicher |
G2-Wertung: 4.5/5 |100 % Sicher |
Einige der wichtigsten Funktionen von PDFelement als PDF Scraper sind:
- Datenextraktion: Mit PDFelement können Sie mithilfe der fortschrittlichen OCR-Technologie (Optical Character Recognition) Daten aus PDF-Dateien extrahieren. Benutzer können Daten aus PDF-Dateien in verschiedenen Formaten extrahieren, darunter Text, Tabellen und Bilder.
- Anpassungen: PDFelement bietet ein hohes Maß an Anpassungsmöglichkeiten für die Datenextraktion, so dass die Benutzer die spezifischen Daten auswählen können, die sie extrahieren möchten. Diese Funktion ist besonders nützlich für Forscher und Unternehmen, die bestimmte Datenpunkte für ihre Analysen extrahieren müssen.
- Automatisierung: PDFelement kann den Prozess der Datenextraktion automatisieren, wodurch der Benutzer Zeit spart und das Risiko von Fehlern, die bei der manuellen Datenextraktion auftreten können, verringert wird.
- Kompatibilität: PDFelement kann Daten aus PDF-Dateien verschiedener Formate und Versionen extrahieren, was es zu einem vielseitigen Tool für die Datenextraktion macht.
- Benutzerfreundliche Oberfläche: PDFelement ist einfach zu bedienen, auch für Benutzer mit begrenzten technischen Kenntnissen. Seine intuitive Oberfläche und sein einfaches Design machen es für viele Benutzer zugänglich.
Wie man PDFelement als PDF Scraper verwendet
Die Verwendung von PDFelement als PDF-Scraper ist ein unkomplizierter Prozess. Hier finden Sie eine Schritt-für-Schritt-Anleitung, wie Sie PDFelement als PDF Scraper verwenden:
Schritt 1
Starten Sie PDFelement und laden Sie Ihr PDF-Formular hoch, indem Sie es per Drag & Drop oder über die Schaltfläche "PDF öffnen" ablegen.
G2-Wertung: 4.5/5 | 100 % Sicher |
G2-Wertung: 4.5/5 |100 % Sicher |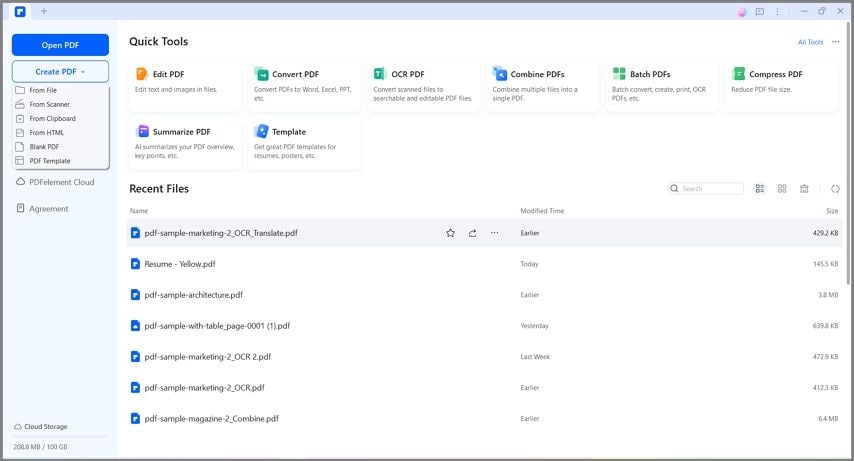
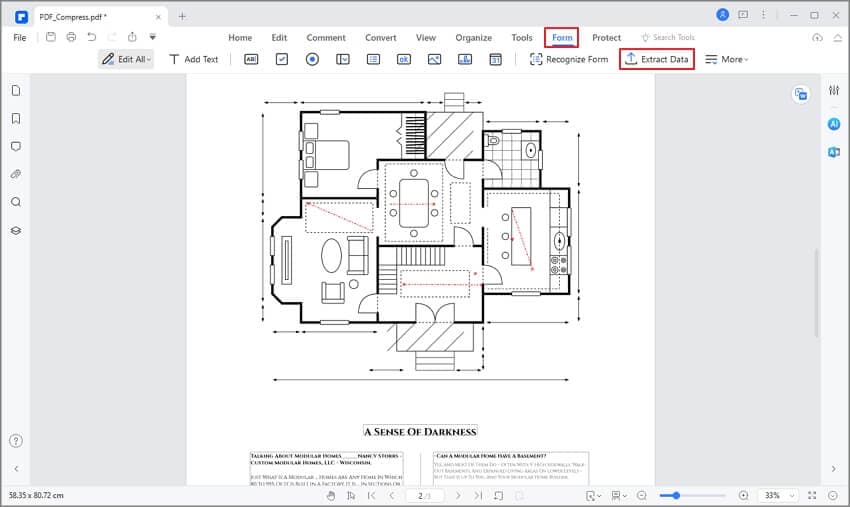
Schritt 2
Klicken Sie auf "Formular" > "Daten extrahieren", um ein neues Dialogfenster zu öffnen.
Schritt 3
Wählen Sie "Daten aus Formularfeldern in PDF extrahieren" und klicken Sie auf "Übernehmen".
G2-Wertung: 4.5/5 | 100 % Sicher |
G2-Wertung: 4.5/5 |100 % Sicher |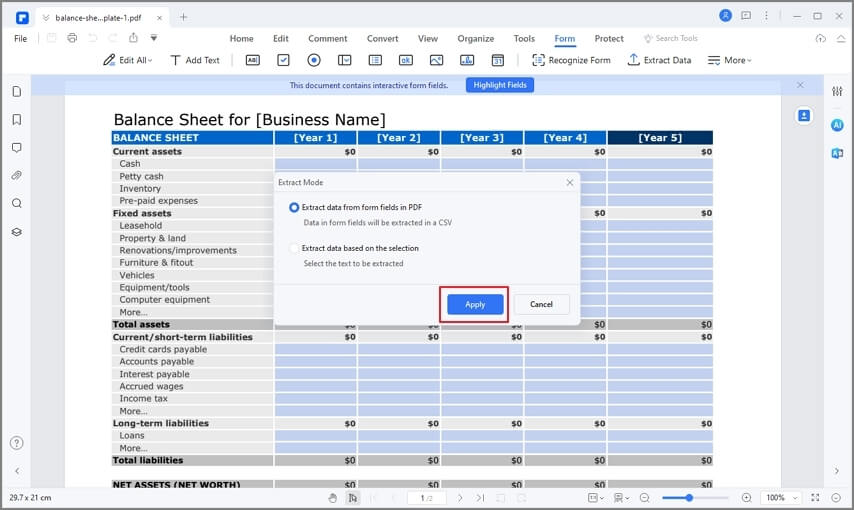
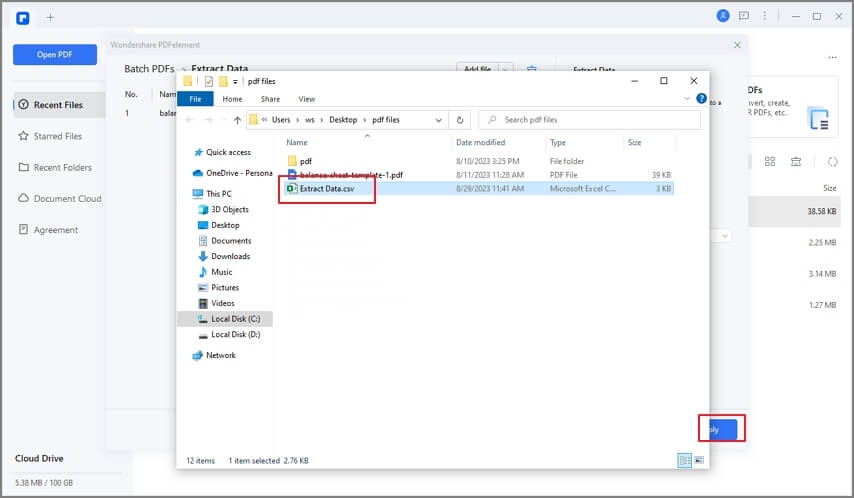
Schritt 4
Das Programm wird die Daten in eine CSV-Datei extrahieren. Klicken Sie auf "Öffnen", um auf die Daten zuzugreifen, wenn der Vorgang abgeschlossen ist.
Hier finden Sie einige Tipps und Tricks für effizientes PDF-Scraping mit PDFelement:
- Verwenden Sie die OCR-Funktion, um Daten aus gescannten PDF-Dateien zu extrahieren, die keinen durchsuchbaren Text enthalten.
- Verwenden Sie die Funktion der Stapelverarbeitung, um Daten aus mehreren PDF-Dateien zu extrahieren.
- Verwenden Sie die Vorlagen für die Datenextraktion, um beim Extrahieren von Daten aus ähnlichen PDF-Dateien Zeit zu sparen.
- Verwenden Sie die Vorschaufunktion, um die extrahierten Daten auf ihre Richtigkeit zu überprüfen, bevor Sie sie in ein anderes Dateiformat exportieren.
Alles in allem ist PDFelement ein leistungsstarkes und benutzerfreundliches Tool zum Scannen von PDFs. Wenn Sie diese Schritte und Tipps befolgen, können Sie effizient Daten aus PDF-Dateien extrahieren und Zeit bei der manuellen Datenextraktion sparen.
Vorteile der Verwendung von PDFelement als PDF Scraper
Für das Scraping von PDFs gibt es mehrere Tools, darunter Adobe Acrobat, Tabula, PDFTables und PDFelement. Jedes Tool hat Stärken und Schwächen, aber PDFelement sticht in vielerlei Hinsicht hervor.
Im Vergleich zu anderen PDF Scraping Tools bietet PDFelement eine benutzerfreundlichere und intuitivere Oberfläche. Der Prozess der Datenextraktion ist einfach und effizient, so dass die Benutzer problemlos Daten aus PDF-Dateien extrahieren können. Die OCR-Funktion von PDFelement ermöglicht auch die Extraktion von Text aus gescannten PDFs, was viele andere PDF Scraping Tools nicht können.
Die Vorlagen für die Datenextraktion von PDFelement sind ebenfalls ein großer Vorteil. Mit dieser Funktion können Benutzer Zeit sparen, indem sie Vorlagen für ähnliche PDF-Dateien erstellen, die dann mit nur wenigen Klicks zum Extrahieren von Daten verwendet werden können. Diese Funktion ist besonders nützlich für Benutzer, die Daten aus mehreren PDF-Dateien mit einer ähnlichen Struktur extrahieren müssen.
Ein weiterer Vorteil von PDFelement als PDF Scraper ist seine Funktion zur Stapelverarbeitung. Benutzer können Daten aus mehreren PDF-Dateien gleichzeitig extrahieren, was Zeit spart und die Produktivität erhöht. Diese Funktion ist besonders nützlich für Unternehmen oder Organisationen, die mit großen Datenmengen arbeiten.
PDFelement bietet außerdem mehrere Exportoptionen, darunter Excel-, CSV- und reine Textformate, so dass Sie die extrahierten Daten problemlos in anderen Programmen oder Softwareprogrammen analysieren können. PDFelement bietet leistungsstarke Tools zur Datenbereinigung und -manipulation, wie z.B. Textformatierung und Tabellenzusammenführung, mit denen Sie die extrahierten Daten für die weitere Analyse vorbereiten können.
G2-Wertung: 4.5/5 | 100 % Sicher |
G2-Wertung: 4.5/5 |100 % Sicher |Szenarien des PDFelement Scrapings
Die Funktionen von PDFelement zum Scraping von Daten sind in einer Vielzahl von Szenarien nützlich. In diesem Abschnitt werden einige der häufigsten Anwendungsfälle untersucht, in denen der PDFelement Scraper besonders nützlich sein kann.
Forschung
Die Forschung ist ein Bereich, der stark von der Datenanalyse abhängt und der PDFelement Scraper kann ein nützliches Tool für die Extraktion und Analyse von Daten aus verschiedenen Quellen sein.
Akademische Artikel und Berichte enthalten oft wertvolle Daten, die Forscher extrahieren und analysieren müssen. Mit dem Scraper von PDFelement können Forscher schnell und präzise Daten aus diesen Dokumenten extrahieren und so den Zeit- und Arbeitsaufwand für die manuelle Dateneingabe reduzieren.
Umfragen und Fragebögen sind gängige Forschungstools, um Daten von Studienteilnehmern zu sammeln. Der Scraper von PDFelement kann Umfragedaten extrahieren und analysieren und spart Forschern wertvolle Zeit und Mühe. Mit PDFelement können Forscher Umfrageergebnisse ganz einfach in ein brauchbares Format konvertieren, z.B. in eine Tabellenkalkulation, was eine einfachere Datenanalyse ermöglicht.
Bei der behördlichen und politischen Forschung werden oft große Datenmengen analysiert, darunter Berichte, politische Dokumente und Gesetzestexte. Der Scraper von PDFelement kann relevante Daten aus diesen Dokumenten extrahieren, so dass politische Entscheidungsträger und Forscher schnell Muster und Trends erkennen können.
Bei der Marktforschung geht es um die Sammlung und Analyse von Daten zum Verbraucherverhalten, zu Markttrends und zu Aktivitäten der Konkurrenz. Der Scraper von PDFelement kann Daten aus Marktforschungsberichten, Social-Media-Analysen und anderen Quellen extrahieren, so dass Unternehmen wertvolle Einblicke in Markttrends und Verbraucherverhalten gewinnen können.
Die medizinische und wissenschaftliche Forschung umfasst die Analyse großer Datenmengen aus verschiedenen Quellen, einschließlich klinischer Testversionen, Krankenakten und Forschungsartikeln. Der Scraper von PDFelement kann relevante Daten aus diesen Dokumenten extrahieren, so dass Forscher Muster und Trends erkennen können, die für die Entwicklung neuer Behandlungen und Therapien nützlich sind.

Business
Der Scraper von PDFelement kann auch für Unternehmen nützlich sein, die Daten aus verschiedenen Quellen extrahieren und analysieren.
Bei der Fakturierung und Rechnungsstellung müssen Sie oft mit großen Datenmengen arbeiten, einschließlich Kundeninformationen und Kaufhistorien. Der Scraper von PDFelement kann diese Daten aus Rechnungen und Abrechnungen extrahieren, so dass Unternehmen die Kaufmuster und Trends ihrer Kunden schnell erkennen können.
Die Finanzberichterstattung umfasst die Analyse von Daten aus verschiedenen Finanzdokumenten, einschließlich Bilanzen, Gewinn- und Verlustrechnungen und Cashflow-Rechnungen. Der Scraper von PDFelement kann relevante Daten aus diesen Dokumenten extrahieren, so dass Unternehmen schnell genaue Finanzberichte erstellen können.
Bei der Marktforschung geht es um die Sammlung und Analyse von Daten zum Verbraucherverhalten, zu Markttrends und zu Aktivitäten der Konkurrenz. Der Scraper von PDFelement kann Daten aus Marktforschungsberichten, Social-Media-Analysen und anderen Quellen extrahieren, so dass Unternehmen wertvolle Einblicke in Markttrends und Verbraucherverhalten gewinnen können.
Die Personalverwaltung umfasst das Sammeln und Analysieren von Daten über die Leistung der Mitarbeiter, ihre Anwesenheit und andere Faktoren. Der Scraper von PDFelement kann relevante Daten aus Leistungsreviews, Stundenzetteln und anderen HR-Dokumenten extrahieren, so dass Unternehmen Trends und Muster im Mitarbeiterverhalten erkennen und datengestützte Entscheidungen treffen können.
G2-Wertung: 4.5/5 | 100 % Sicher |
G2-Wertung: 4.5/5 |100 % Sicher |Rechtswesen
Der Scraper von PDFelement kann auch ein wertvolles Tool für Juristen sein, die Daten aus verschiedenen juristischen Dokumenten extrahieren und analysieren möchten.
Die Ermittlung ist ein wichtiger Teil des juristischen Prozesses, bei dem Anwälte große Mengen an Daten aus verschiedenen Quellen sammeln und analysieren müssen. Der Scraper von PDFelement kann Daten aus juristischen Dokumenten wie Verträgen, Vereinbarungen und Gerichtsakten extrahieren, so dass Anwälte schnell relevante Informationen identifizieren und ihre Fälle besser vorbereiten können.
Das Vertragsmanagement ist ein wichtiger Bestandteil vieler juristischer Praktiken, die das Review und die Analyse großer Verträge und Vereinbarungen beinhalten. Der Scraper von PDFelement kann relevante Daten aus diesen Dokumenten extrahieren, so dass Anwälte die wichtigsten Bedingungen und Bestimmungen schnell identifizieren, die Einhaltung von Verträgen überwachen und Risiken verwalten können.
Das Recht des geistigen Eigentums schützt und verwaltet wertvolle Assets des geistigen Eigentums, darunter Patente, Marken und Urheberrechte. Der Scraper von PDFelement kann Daten aus IP-Dokumenten extrahieren, so dass Anwälte schnell relevante Informationen identifizieren und den Status von IP-Assets überwachen können.
Bei der juristischen Recherche werden Daten aus verschiedenen Quellen analysiert, darunter Rechtsprechung, Gesetze und Vorschriften. Der Scraper von PDFelement kann relevante Daten aus diesen Quellen extrahieren, so dass Anwälte schnell relevante Informationen finden und stärkere juristische Argumente aufbauen können.
Fazit
Die PDFelement-Funktionen zum Scraping von PDFs bieten ein leistungsstarkes Tool für die Datenextraktion und -analyse. Es bietet eine benutzerfreundliche Oberfläche und eine breite Palette von Funktionen, die es zu einer ausgezeichneten Wahl für Forscher, Wirtschaftsanalysten und Juristen machen. Seine Fähigkeit, Daten genau und schnell aus PDFs zu extrahieren, kann Zeit sparen und die Produktivität steigern. PDFelement ist eine kostengünstige Lösung für Unternehmen, die häufig Daten aus PDFs extrahieren müssen, um ihre Effizienz zu steigern und ihren Workflow zu optimieren.
