
Das Extrahieren von Daten aus PDF-Dateien ist in vielen Branchen, darunter im Finanzwesen, im Gesundheitswesen und in der Forschung, eine häufige Anforderung. Da Organisationen für den Informationsaustausch zunehmend auf PDFs zurückgreifen, ist die Notwendigkeit gestiegen, Daten aus PDFs mit Python zu extrahieren. Die manuelle Datenextraktion kann jedoch zeitaufwendig und fehleranfällig sein, was zu Ineffizienzen und Ungenauigkeiten bei der Datenverarbeitung führt.
In diesem Artikel
- Warum sollten Daten aus PDFs mit Python extrahiert werden?
- Wichtige Bibliotheken für die PDF-Datenextraktion in Python
- PDFelement: Vereinfachen Sie den gesamten Prozess der PDF-Datenextraktion
- Vorteile von PDFelement im Vergleich zur manuellen Python-Skripterstellung
- Wie PDFelement reibungslos mit Python zusammenarbeitet
- Schritt-für-Schritt-Anleitung zum Extrahieren von Daten aus PDFs mit Python und PDFelement
- Vorteile der Kombination von PDFelement mit Python
Python hat als leistungsstarkes Tool zur Extraktion von Daten aus PDF-Dateien enorm an Beliebtheit gewonnen. Mit seinen umfangreichen Bibliotheken und seiner benutzerfreundlichen Syntax vereinfacht Python das Extrahieren von Daten aus PDF-Dateien. In diesem Artikel wird gezeigt, wie Python in Kombination mit Tools wie PDFelement die Extraktion von PDF-Daten in Python einfacher und effizienter macht.
Warum sollten Daten aus PDFs mit Python extrahiert werden?
Die Möglichkeiten von Python bei der Verarbeitung von PDFs sind dank seines umfangreichen Ökosystems an Bibliotheken, die speziell für die PDF-Datenextraktion in Python entwickelt wurden, sehr umfangreich. Diese Bibliotheken bieten verschiedene Funktionen, die unterschiedliche Extraktionsanforderungen erfüllen. Hier einige nennenswerte Bibliotheken:
PyPDF2
Diese Bibliothek ermöglicht die grundlegende Textextraktion und Bearbeitung von PDF-Dateien und ist somit ein hervorragender Ausgangspunkt für Benutzer, die mit Python Daten aus PDF-Dateien extrahieren möchten, ohne dass eine komplexe Formatierung erforderlich ist.
PyMuPDF (Fitz)
Dieses Programm extrahiert effektiv Text und Anmerkungen. Es bietet mehr Funktionen als PyPDF2 und eignet sich hervorragend zum Extrahieren strukturierter Informationen. Damit ist es ideal für Dokumente, die neben dem Text auch Bilder oder Anmerkungen enthalten.
PDFMiner
Diese Bibliothek bietet fortschrittliche Funktionen zum Extrahieren von Text unter Beibehaltung der Layout-Struktur und eignet sich daher perfekt für komplexe Dokumente. Sie erhalten detaillierte Informationen über die Position und Formatierung des Textes, was bei der Arbeit mit komplizierten Layouts sehr wichtig ist.
Wichtige Bibliotheken für die Extraktion von PDF-Daten in Python
PyPDF2
PyPDF2 ist eine weit verbreitete Bibliothek, die wesentliche Funktionen zum Lesen und Bearbeiten von PDF-Dateien bietet. Sie ist besonders nützlich für Benutzer, die mit Python Daten aus PDFs extrahieren möchten.
Was sie tun kann:
- Text extrahieren: Diese Funktion extrahiert Text aus einzelnen Seiten eines PDF-Dokuments und ermöglicht so einen einfachen Zugriff auf den Inhalt.
- PDFs zusammenführen oder aufteilen: Kombinieren Sie mehrere PDF-Dokumente in einer einzigen Datei oder teilen Sie ein großes PDF in kleinere, überschaubare Abschnitte auf.
Beispiele für die Verwendung:
- Wenn Sie Text aus einfachen PDFs ohne komplexes Layout extrahieren müssen, z. B. aus Berichten oder Rechnungen.
- Das Zusammenführen mehrerer PDFs in einem einzigen Dokument ist hilfreich, um zusammengehörige Dateien zu organisieren.
PyMuPDF (Fitz)
PyMuPDF, auch bekannt als Fitz, ist eine leistungsstarke Bibliothek zum Extrahieren von Text und Anmerkungen aus PDF-Dokumenten. Ihre fortschrittlichen Funktionen machen sie zu einer bevorzugten Wahl für Benutzer, die komplexere Aufgaben zur Extraktion von Python PDF-Daten durchführen müssen.
Fähigkeiten:
- Effiziente Textextraktion: Extrahiert Text unter Beibehaltung des Layouts und stellt sicher, dass die Ausgabe die ursprüngliche Formatierung beibehält.
- Zugriff auf Bilder und Medien: Mit dieser Funktion können Benutzer Bilder und andere in das PDF eingebettete Medien extrahieren, was es ideal für visuell umfangreiche Dokumente macht.
Ideale Anwendungsfälle:
- Wenn Sie detaillierte Informationen neben Bildern oder Anmerkungen benötigen, z. B. in akademischen Dokumenten oder Marketingmaterialien.
- Für die Extraktion von Inhalten aus visuell umfangreichen PDF-Dateien, bei denen die Erhaltung des Layouts entscheidend ist.
PDFMiner
PDFMiner ist eine fortschrittliche Bibliothek, die speziell für die Extraktion detaillierter Informationen aus PDFs entwickelt wurde, einschließlich Layout und Struktur des Textes. Es ist besonders vorteilhaft für Benutzer, die genau kontrollieren möchten, wie Daten aus ihren Dokumenten extrahiert werden.
Funktionen:
- Layout-Erhaltung: Kann Text zusammen mit seinen Layout-Informationen extrahieren und ist damit ideal für komplexe Dokumente, bei denen die Struktur wichtig ist.
- Erweiterte Textanalyse: Bietet Tools zur Analyse des Layouts von Dokumenten, was bei der Formatierung von Bedeutung sein kann.
Wann zu verwenden:
- Wenn Sie eine genaue Kontrolle darüber benötigen, wie der Text abhängig von seiner Position im Dokument extrahiert wird, z. B. bei juristischen Verträgen oder technischen Handbüchern.
- Für die Analyse des Layouts von Dokumenten, bei denen die Formatierung von entscheidender Bedeutung ist, um sicherzustellen, dass die extrahierten Daten ihre beabsichtigte Struktur beibehalten.
Pandas für tabellarische Daten
Die Integration von Pandas mit anderen Bibliotheken kann bei der Extraktion von strukturierten Tabellendaten aus PDFs von großem Nutzen sein. Pandas ermöglicht es Ihnen, die extrahierten Daten effizient zu verwalten und zu analysieren, was es zu einem unverzichtbaren Tool in Ihrem Python Toolkit für die Extraktion von Daten aus PDFs mit Python macht.
Vorteile:
- Datenmanipulation: Bearbeiten Sie große Datensätze, die aus PDFs extrahiert wurden, und erleichtern Sie so die weitere Analyse und Berichterstattung.
- Komplexe Analysen: Führen Sie mit minimalem Aufwand komplexe Analysen auf strukturierten Daten durch, indem Sie die leistungsstarken Datenverarbeitungsfunktionen von Pandas nutzen.
Mit diesen Bibliotheken - PyPDF2, PyMuPDF (Fitz), PDFMiner und Pandas - können Anwender mit Python effektiv Daten aus PDF extrahieren, die auf ihre speziellen Bedürfnisse zugeschnitten sind. Ganz gleich, ob Sie einfachen Text oder komplexe Tabellen extrahieren, das robuste Ökosystem von Python bietet die notwendigen Tools für eine effiziente Extraktion von PDF-Daten in Python.
PDFelement: Vereinfachen Sie den gesamten Prozess der PDF-Datenextraktion
PDFelement ist ein umfassender PDF Editor mit einer Reihe von Funktionen, die die Dokumentenverwaltung vereinfachen. Er bietet benutzerfreundliche Tools zum reibungslosen Erstellen, Bearbeiten, Konvertieren und Extrahieren von Daten aus PDFs.
Vorteile von PDFelement im Vergleich zur manuellen Python-Skripterstellung
Die Verwendung von PDFelement bietet mehrere Vorteile gegenüber herkömmlichen manuellen Skriptmethoden:
- Benutzerfreundliche Oberfläche: PDFelement ist einfach zu bedienen, auch für diejenigen, die keine Erfahrung im Programmieren haben. Diese Zugänglichkeit macht es zu einer guten Wahl für Einzelpersonen oder Teams, die vielleicht keine Programmierkenntnisse haben, aber dennoch effektive Tools zum Extrahieren von Daten aus PDFs mit Python benötigen.
- OCR-Technologie: Es enthält Funktionen zur optischen Zeichenerkennung (OCR), mit denen Sie effektiv Text aus gescannten PDFs extrahieren können. Diese Funktion ist besonders wertvoll für digitalisierte physische Dokumente.
- Exportoptionen: Sie können die extrahierten Daten in strukturierte Formate wie Excel, CSV oder Word exportieren. Python-Bibliotheken können diese Formate dann schnell verarbeiten, was eine reibungslose Integration in bestehende Workflows ermöglicht.
Wie PDFelement reibungslos mit Python funktioniert
Sie können Daten über die intuitive Oberfläche von PDFelement extrahieren und dann mit Python-Skripten für weitere Analysen nachbearbeiten. Diese Kombination verbessert Ihren Workflow, indem sie die Stärken beider Tools nutzt - PDFelement vereinfacht den Extraktionsprozess, während Python eine erweiterte Manipulation und Analyse der extrahierten Daten ermöglicht.
Schritt-für-Schritt-Anleitung zum Extrahieren von Daten aus PDFs mit Python und PDFelement
Python verwenden
Um mit der Extraktion von Daten mit Python zu beginnen, müssen Sie zunächst die erforderlichen Bibliotheken installieren:
bash
pip install pypdf2 pymupdf pdfminer.six pandas
Einfaches Codebeispiel zum Extrahieren von Text- oder Tabellendaten
Hier ist ein einfaches Beispiel, das zeigt, wie Sie mit PyPDF2 Text extrahieren können:
python
from PyPDF2 import PdfReader
# Laden der PDF-Datei
reader = PdfReader('example.pdf')
# Text von jeder Seite extrahieren
for page in reader.pages:
print(page.extract_text())
Einschränkungen der reinen Python-Extraktion
Die Verwendung von Python-Bibliotheken für die Extraktion von PDF-Daten bietet zwar Flexibilität, aber es gibt auch erhebliche Einschränkungen:
- Probleme mit gescannten Dokumenten: Standardbibliotheken können gescannte Dokumente ohne OCR-Funktionen nicht effektiv verarbeiten. Dies ist ein erheblicher Nachteil, wenn Sie versuchen, mit Python Daten aus PDF-Dateien zu extrahieren, insbesondere wenn die Dokumente hauptsächlich bildbasiert sind.
- Verlust der Datenstruktur: Das Extrahieren von Tabellen kann zum Verlust der Formatierung oder der Struktur führen, wenn sie nicht speziell behandelt wird. Dies kann die weitere Analyse erschweren, wenn das ursprüngliche Layout von Bedeutung ist. Viele Benutzer stoßen bei der Extraktion von Daten aus PDF mit Python auf Schwierigkeiten, insbesondere bei komplexen Tabellen, die eine präzise Formatierung erfordern.
PDFelement zum Extrahieren von Daten verwenden
So extrahieren Sie effektiv Daten aus PDF mit PDFelement:
Schritt 1
Öffnen Sie PDFelement und laden Sie Ihr PDF-Dokument.
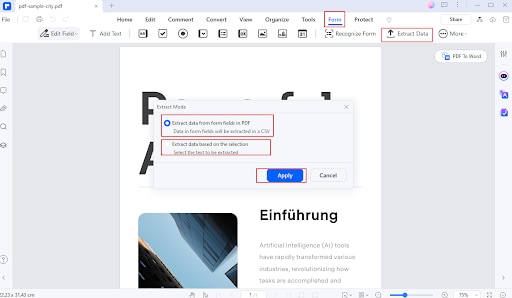
Schritt 2
Navigieren Sie zur Registerkarte Formular und wählen Sie Daten extrahieren.
Schritt 3
Wählen Sie die gewünschten Extraktionsoptionen (z.B. Formularfelder oder Tabellen).
Vorteile der Kombination von PDFelement mit Python
Die Integration von PDFelement mit Python bietet mehrere Vorteile für Benutzer, die ihre PDF-Datenextraktion in Python verbessern möchten:
- Effizienzsteigerung: Die Kombination der intuitiven Oberfläche von PDFelement mit der Flexibilität von Python steigert die Produktivität, da sich die Benutzer auf die Analyse und nicht auf die Extraktionslogistik konzentrieren können. Diese Kombination ist besonders für diejenigen von Vorteil, die regelmäßig Daten aus PDFs mit Python extrahieren müssen.
- Verbesserte Genauigkeit: PDFelement nutzt die OCR-Unterstützung für eine genaue Extraktion aus gescannten PDFs, mit der Standardbibliotheken oft Schwierigkeiten haben. Diese Funktion ist von entscheidender Bedeutung, um sicherzustellen, dass wichtige Daten während des Extraktionsprozesses nicht verloren gehen.
- Zeitersparnis: Automatisieren Sie sich wiederholende Aufgaben, indem Sie beide Tools effektiv nutzen. Verwenden Sie zum Beispiel PDFelement für erste Extraktionen und wenden Sie dann Python-Skripte für tiefergehende Analysen oder Berichte an. Auf diese Weise können Unternehmen ihre Workflows rationalisieren und die Gesamteffizienz bei der Verwaltung mehrerer PDF-Dokumente verbessern.
Diese Kombination ist besonders ideal für Unternehmen, die mit mehreren PDF-Dokumenten und komplexen Datensätzen arbeiten, bei denen Effizienz und Genauigkeit bei der PDF-Datenextraktion für Python von größter Bedeutung sind.
 G2-Wertung: 4.5/5 |
G2-Wertung: 4.5/5 |  100 % Sicher |
100 % Sicher |
 G2-Wertung: 4.5/5 |100 % Sicher |
G2-Wertung: 4.5/5 |100 % Sicher |Fazit
Es gibt verschiedene Optionen für die Extraktion von Daten aus PDFs mit Python, darunter Bibliotheken wie PyPDF2, PyMuPDF und PDFMiner. PDFelement zeichnet sich jedoch durch seine Fähigkeit aus, den Extraktionsprozess mit benutzerfreundlichen Funktionen und leistungsstarken Funktionen zu rationalisieren, was es zu einer hervorragenden Wahl für die Verbesserung der Verwaltung von PDF-Dokumenten macht. Darüber hinaus bietet DocuSign eine unkomplizierte Methode zur Ablehnung der Unterzeichnung von Dokumenten, die ebenfalls in Ihren Workflow integriert werden kann, um die Effizienz der Bearbeitung von PDF-Daten weiter zu verbessern.
