Anwendung von OCR bei der Archivdigitalisierung
Der Artikel stellt vor, wie OCR als Prozess angewendet wird und wie die Genauigkeit von OCR durch verschiedene Methoden verbessert werden kann.

2025-03-21 14:12:34 • Abgelegt unter: OCR Funktion • Bewährte Lösungen
Die PDF-Technologie hat die Digitalisierung von Archiven in den letzten Jahrzehnten stark vorangetrieben. Was früher eine Herausforderung für die Datenaufbewahrung und die Speicherung von Dokumenten zum einfachen Abruf war, ist heute alltäglich geworden. Einer der Schlüsselfaktoren für diesen Wandel ist die OCR (optische Zeichenerkennung). Wir wollen sehen, warum OCR bei der Digitalisierung von Archiven eine so wichtige Rolle spielt, wie sie als Verfahren angewendet wird und wie die Genauigkeit von OCR durch verschiedene Methoden verbessert werden kann.
 G2-Wertung: 4.5/5 |
G2-Wertung: 4.5/5 |  100 % Sicher |
100 % Sicher |
 G2-Wertung: 4.5/5 |100 % Sicher |
G2-Wertung: 4.5/5 |100 % Sicher |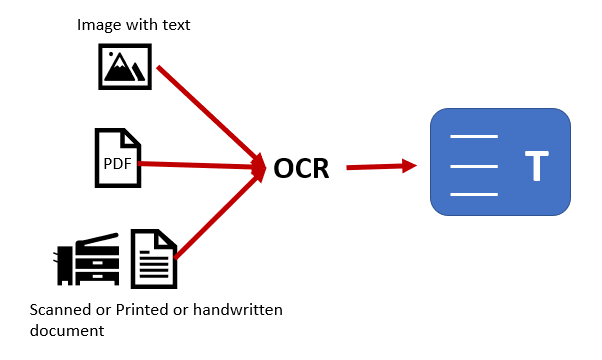
Teil 1. Anwendung von OCR bei der Archivdigitalisierung
OCR ist im Wesentlichen der Prozess des Erkennens, Extrahierens und Einbettens des Textinhalts aus einem bildbasierten digitalen oder physischen Dokument in die vorhandene Bildebene. Diese zweischichtige Technologie wird von PDF unterstützt, was es zu einem idealen Medium für die Digitalisierung von Archiven macht. Es gibt noch eine Reihe weiterer Überlegungen, die PDF zum idealen Medium für die Digitalisierung von Dokumentenarchiven machen.
1. Innovation bei traditionellen Katalogisierungs- und Indexierungsmethoden
Katalogisierung und Indexierung gehen oft Hand in Hand, sind aber zwei völlig unterschiedliche Prozesse. Während es beim Katalogisieren um die Organisation von Assets oder Inhalten geht, bezieht sich das Indexieren auf das Abrufen von Informationen. Beides ist für die Archivierung von Dokumenten, audiovisuellen Medien, Zeitungen, Magazinen, Fachzeitschriften und anderen Inhalten erforderlich. Die Katalogisierung zeigt Ihnen, was vorhanden ist, während die Indexierung eine Möglichkeit bietet, die gesuchten Informationen zu finden.
Die Konvertierung von physischen Dokumenten oder gescannten Dateien in das PDF-Format ermöglicht die gleichzeitige Katalogisierung und Indexierung mithilfe der OCR-Technologie. Die digitalisierten Inhalte können bearbeitet oder durchsuchbar gemacht werden, was eine einfache Katalogisierung und Indexierung der Archive ermöglicht. OCR ist daher ein neuer Weg, um Dokumentenarchive zu katalogisieren und zu indexieren, indem der Prozess über Computer zugänglich gemacht wird.
2. Verwirklichung einer echten Volltextsuche
Die manuelle Indexierung ist in der Regel anfällig für menschliche Fehler, die je nach Aufgabe zwischen 3 % und 30 % liegen können. Das bedeutet, dass textbasierte Dokumente möglicherweise nicht richtig indiziert werden, wenn der Prozess manuell durchgeführt wird. Das Gleiche gilt auch für die Katalogisierung, allerdings in geringerem Maße. Mit Hilfe von OCR ist jedoch eine Konvertierung mit einer Genauigkeit von 98 % bis 99 % möglich. Dies wiederum ermöglicht eine Volltextsuche und -abfrage. Wenn diese Fähigkeit mit Metadaten und Indexierungselementen kombiniert wird, ergibt sich ein verbessertes Katalogisierungs- und Indexierungssystem.
3. Doppellagige PDF-Technologie
Obwohl allgemein angenommen wird, dass OCR eine Textebene in das vorhandene Bild einbettet, wird der Text in Wirklichkeit als unsichtbarer Text in der PDF-Datei wiedergegeben. Dieser Text kann nun jedoch ausgewählt werden und ist somit durchsuchbar. Bei der Archivdigitalisierung prüft der Archivar zunächst, ob die digitalisierte Textebene mit dem Text im Originalbild übereinstimmt. Dieser Qualitätssicherungsschritt ist entscheidend für die Genauigkeit des gerenderten Textes. Diese Änderungen werden dann in der OCR-Kopie der Datei gespeichert, was die Suche nach Schlüsselwörtern erleichtert. Alle Tippfehler, die bei dieser Qualitätskontrolle übersehen werden, führen dazu, dass das Dokument nicht nach dem betreffenden Stichwort durchsucht werden kann. Das ist der Punkt, an dem die Schichtung ins Spiel kommt. Damit kann der Archivierer visuell prüfen, ob die von der OCR-Engine erkannten Zeichen mit den Zeichen in der bildbasierten Originaldatei übereinstimmen.
4. Ausweitung der Nutzung von archivierten Dateien
Durch OCR in einem PDF-Dokument wird eine durchsuchbare Ebene erzeugt, aber der Text kann auch editierbar gemacht werden. Für die Zwecke der Archivierung und des Abrufs wird jedoch ein durchsuchbares Dokument bevorzugt, da die Indizierungsinformationen bei der Rückgabe von Volltextsuchergebnissen hilfreich sein können. Dies wiederum ermöglicht die Verwendung von OCR-Dokumenten in einer Vielzahl von Szenarien, je nachdem, ob sie bearbeitbar oder durchsuchbar sind. So ist es zum Beispiel viel einfacher, einen Text in einer bildbasierten Datei mit OCR zu korrigieren als denselben Text in einem Bildbearbeitungstool. OCR eröffnet eine Reihe von Anwendungsfällen, die mit herkömmlichen Archivierungstechniken nicht möglich sind.
Teil 2. Wie man die OCR-Erkennungsrate verbessert
Die Genauigkeit eines OCR-Laufs hängt von verschiedenen softwarebasierten und manuellen Überlegungen ab, die im Folgenden aufgeführt sind. Jeder dieser Parameter ermöglicht eine genauere OCR und sie können entweder in der Phase vor der OCR oder in der Phase nach der OCR im Rahmen der Qualitätssicherung kontrolliert werden.
1. Die richtige Software verwenden - PDFelement
Das OCR-Plugin in Wondershare PDFelement - PDF Editor ist hochpräzise und arbeitet mit mehreren Sprachen, auch gleichzeitig. Darüber hinaus bietet PDFelement die Konvertierung in durchsuchbare und bearbeitbare Versionen der ursprünglichen PDF-Datei. Es kann auch direkt eine PDF-Datei aus der Eingabe eines Scanners erstellen sowie Nicht-Text-Dateiformate in bearbeitbare/durchsuchbare PDF-Dateien konvertieren.
G2-Wertung: 4.5/5 | 100 % Sicher |
G2-Wertung: 4.5/5 |100 % Sicher |2. Die richtigen Scan-Parameter
Beim Scannen von Dokumenten ist es wichtig, dass Sie die richtigen Parameter in den Scannereinstellungen festlegen. Einige von ihnen sind. An erster Stelle steht dabei die Orientierung. Stellen Sie sicher, dass das Dokument im richtigen Winkel in den Scanner eingezogen wird, da ein schräger Scan die OCR-Genauigkeit erheblich beeinträchtigen kann.
3. Auflösungseinstellung
Die beste Auflösung für eine genaue OCR ist 300 dpi (Punkte pro Zoll). Diese höhere Dichte ermöglicht einen engmaschigeren Scan, so dass die OCR-Engine im Vergleich zu 150 dpi mit doppelt so vielen Referenzpunkten arbeiten kann.
4. Auswahl des Farbmodus
Für verfärbte oder alte Dokumente ist RGB der empfohlene Farbmodus, damit der Scanner den Inhalt des physischen Dokuments vollständig erfassen kann. Im Allgemeinen ist jedoch das Scannen im Graustufenmodus die beste Option für die OCR-Genauigkeit. Der Schwarz-Weiß-Modus hilft zwar, das Bild schneller zu scannen, kann aber die Qualität der Texterkennung beeinträchtigen.
5. Helligkeits- und Kontrasteinstellungen
Bei der Helligkeit können beide Extreme - zu hoch oder zu niedrig - die OCR-Qualität und -Genauigkeit negativ beeinflussen. Aus diesem Grund ist die empfohlene Helligkeitseinstellung 50 %. Dies hängt jedoch auch vom Scanner selbst ab, so dass mit einer anfänglichen Versuch-und-Irrtum-Phase gerechnet werden muss.
In Bezug auf den Kontrast wird in der Regel die höchste Einstellung bevorzugt, da OCR im Wesentlichen durch die Analyse von dunklen und hellen Bereichen arbeitet, um einzelne Zeichen zu identifizieren. Anschließend werden Regeln angewendet, um diese Ergebnisse mit bekannten Zeichen, Texten und Zahlen abzugleichen. Wenn der Kontrast zwischen dem dunklen Teil des Textes und den umgebenden Nicht-Text-Teilen hoch ist, ist die OCR genauer.
6. Bildkorrektur und Dekontamination
Diese beiden Komponenten haben großen Einfluss auf die Qualität des OCR-Scannens. Die Bildkorrektur umfasst Aspekte wie die Erhöhung der Auflösung, die Anwendung von Farbkorrekturen und das Ausprobieren verschiedener Kontrasteinstellungen, während die Dekontamination die Entfernung von Nicht-Text-Zeichen wie Icons, Nicht-Text-Bildern, ungewöhnlichen Zeichen, etc. umfasst. Beides ist wichtig, weil die OCR-Engine dadurch das Dokument genauer "lesen" kann.
7. Sorgfältiges manuelles Lektorat
Je nachdem, wie genau Sie das Endergebnis haben möchten, ist ein manuelles Korrekturlesen erforderlich oder nicht. Wenn die Genauigkeit im Vordergrund steht, ist dies ein unverzichtbarer Schritt im Prozess der Archivdigitalisierung. Im Wesentlichen handelt es sich um eine menschliche Überprüfung, um sicherzustellen, dass die gescannten Zeichen im Kontext des gescannten Bildes richtig erkannt werden. Das ist ein langwieriger und mühsamer Prozess, aber in vielen Fällen unerlässlich.
PDFelement - Die beste OCR-Software für die Archivdigitalisierung
PDFelement bietet nicht nur eine hochpräzise OCR-Engine, sondern bringt noch weitere Vorteile bei der Digitalisierung von Archiven mit sich. Hier sind einige der Funktionen, die sie zur perfekten Software für die OCR von PDFs und Scans machen.
G2-Wertung: 4.5/5 | 100 % Sicher |
G2-Wertung: 4.5/5 |100 % Sicher |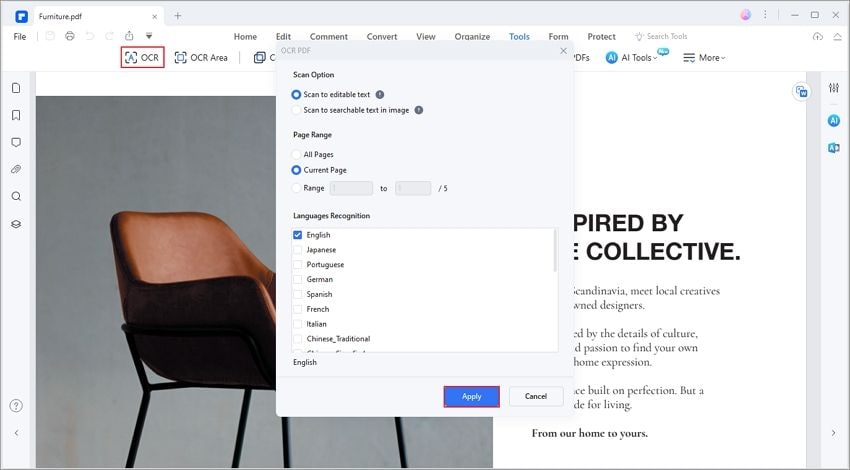
- Vollständige Bearbeitungsmöglichkeiten - Nach der Konvertierung in ein bearbeitbares PDF kann ein Dokument mit den Bearbeitungstools für Bilder, Text, Tabellen, Diagramme, Fuß-/Kopfzeilen, Wasserzeichen, Hyperlinks und andere Inhalte leicht geändert werden.
- Mehrsprachige OCR - Wenn Sie ein Dokument mit mehr als einer Sprache haben, können Sie PDFelement getrost für den OCR-Prozess verwenden. Sie unterstützt über 20 Sprachen, was die Genauigkeit der Texterkennung insgesamt erhöht.
- Stapel Prozess - OCR kann für einen Stapel von Dokumenten durchgeführt werden und spart so Zeit im digitalen Archivierungsprozess.
- Anmerkungen - Konvertierte Dateien können mit Anmerkungen, Hervorhebungen und anderen Inhalten versehen werden, was den Indizierungsprozess erleichtert. Die Anmerkungsliste und das Registerkarten-Layout von PDFelement erleichtern das Querverweisen von Texten bei der Recherche zu einem bestimmten Thema mit OCR-Dateien.
- E-Signing und Sicherheit - Die Dateien können digital oder elektronisch signiert und durch eine passwortbasierte Verschlüsselung vor unbefugter Einsichtnahme oder Bearbeitung geschützt werden. Dies trägt dazu bei, die Echtheit eines Dokuments zu überprüfen und verhindert, dass Änderungen vorgenommen werden. Die Redigierung ist eine weitere nützliche Funktion, mit der Benutzer verhindern können, dass sensible Informationen durchsuchbar sind.
- Organisation von Dateien und Seiten - Einfache Möglichkeiten zum Teilen und Zusammenführen von Dateien, Erstellen von PDF-Portfolios, Vergleichen von Dokumenten nach OCR, Hinzufügen/Löschen/Anordnen von Seiten, Extrahieren von Seiten, etc.
- Reduzierung der Dateigröße - Die PDF-Optimierungsfunktion in PDFelement hilft Archivaren, große Mengen an Informationen auf sehr effiziente Weise zu speichern.
Aus diesen und anderen Gründen gilt PDFelement als einer der besten PDF-Editoren für OCR und verwandte Aufgaben. Die Software ist außerdem eines der erschwinglichsten Premium-PDF-Dienstprogramme für kleine Unternehmen sowie für Organisationen auf Unternehmensebene, was sie zu einer praktikablen Lösung für Unternehmen, Bildungseinrichtungen und alle Arten von Einrichtungen im staatlichen, öffentlichen und privaten Sektor macht.
Kostenlos Downloaden oder PDFelement kaufen jetzt sofort!
Kostenlos Downloaden oder PDFelement kaufen jetzt sofort!
PDFelement kaufen jetzt sofort!
PDFelement kaufen jetzt sofort!

Noah Hofer
staff Editor