Ich arbeite häufig für das US-Patentamt und habe dabei oft mit Dokumenten zu tun, auf die noch kein OCR angewendet wurde. Kann mir jemand ein gutes Programm für die OCR-Stapelverarbeitung von PDF-Dateien empfehlen? Genauigkeit ist wichtig. Gibt es Vorschläge oder Empfehlungen?
Bei der Anwendung von OCR werden gescannte PDF-Dateien mit Hilfe von OCR-Technologie (Optische Zeichenerkennung) durchsuchbar und bearbeitbar gemacht. Vielleicht möchten Sie OCR auf zahlreiche Dateien innerhalb weniger Stunden anwenden und suchen nach einem schnellen Weg dazu. Die Lösung dafür liegt in der Stapelverarbeitung von OCR mit einer Software. Doch Sie haben Glück, denn in diesem Leitfaden zeigen wir Ihnen zwei Möglichkeiten zur Stapelkonvertierung von PDFs in durchsuchbare PDF-Dateien unter Verwendung von PDFelement und Adobe Acrobat.
 100% sicher | Werbefrei | Keine Malware
100% sicher | Werbefrei | Keine MalwareWie Sie OCR-PDF-Dateien im Stapelmodus verarbeiten
Der erste Weg zum Anwenden von OCR auf PDFs im Stapelmodus besteht in der Verwendung von PDFelement. Laden Sie die Software in einer mit Ihrem Betriebssystem kompatiblen Version herunter und installieren Sie sie. Nach der Installation halten Sie sich einfach an diese Anleitung, um einen schnellen Weg zur OCR-Stapelverarbeitung kennenzulernen.
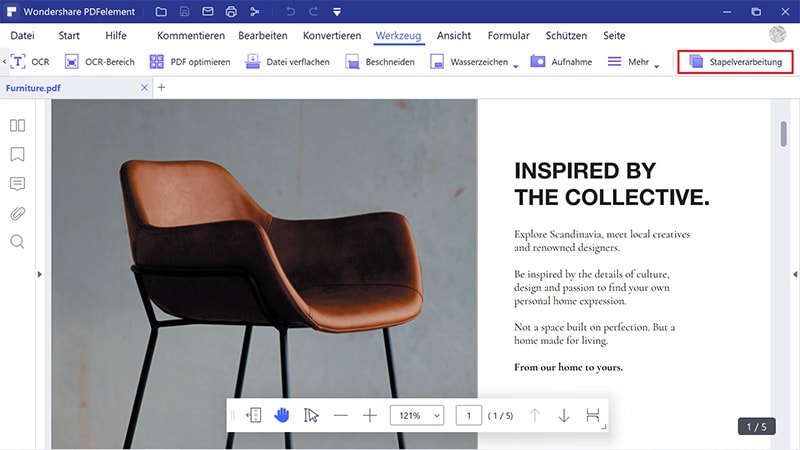
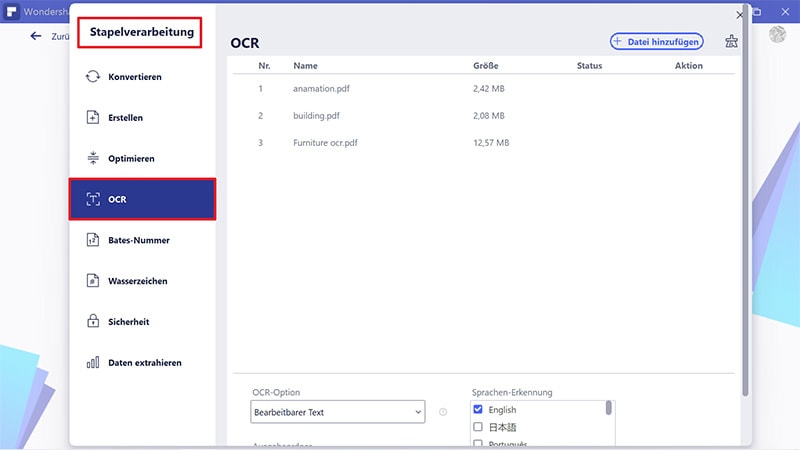
Schritt 1. Klicken Sie auf „Batch-Prozess“
Öffnen Sie die Anwendung zunächst auf Ihrem Computer. Nun öffnet sich der Startbildschirm der Anwendung. Klicken Sie auf die Option „Batch-Prozess“ und fahren Sie mit dem nächsten Schritt fort.
Schritt 2. Mehrere gescannte Dateien hinzufügen
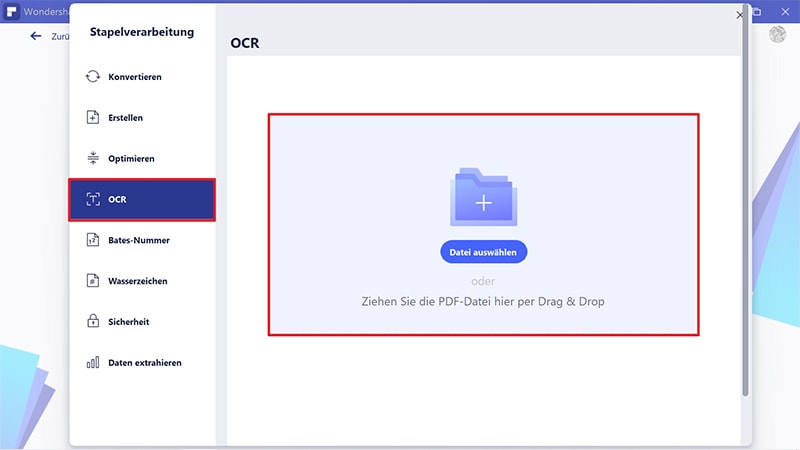
Klicken Sie im Fenster für die Stapelverarbeitung auf „OCR“ und dann auf „PDF-Dateien hier hinzufügen“. Wählen Sie nun alle gewünschten PDF-Dateien aus und fügen Sie sie zum Programm hinzu. Idealerweise sollten Sie die PDF-Dateien zuvor in einem Ordner sammeln, um sie auf einmal hochladen zu können.
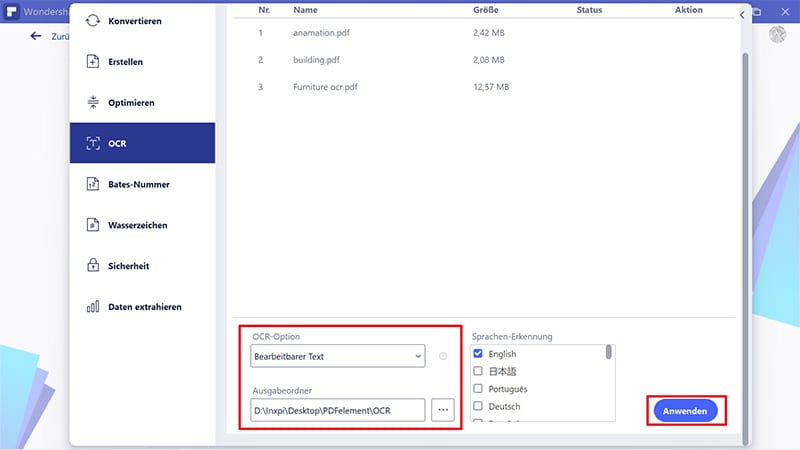
Schritt 3. Stapel-OCR-Sprache auswählen
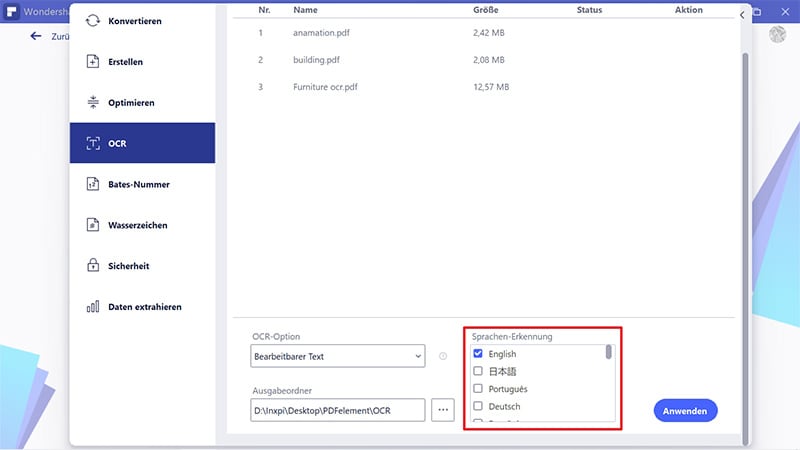
Nachdem Sie die PDF-Dateien in das Programm geladen haben, müssen Sie eine Sprache für das Anwenden von OCR auswählen. Diese hängt in der Regel von der Dokumentensprache ab. Wechseln Sie rechts auf die OCR-Option und wählen Sie die aktuelle Sprache, z.B. „Englisch“.
Schritt 4. Ausgabeordner für Stapel-OCR festlegen
Im nächsten Schritt müssen Sie den Ausgabeordner für die OCR-Stapelverarbeitung festlegen. Direkt unter der OCR-Sprachoption finden Sie außerdem die Ausgabeoption. Aktivieren Sie „Ein Ordner auf meinem Computer“, wenn Sie den Zielordner ändern möchten. Um den aktuellen Ordner beizubehalten, aktivieren Sie ansonsten „Der beim Start ausgewählte Ordner“.
Klicken Sie abschließend auf „Start“, um OCR auf die PDF-Dateien anzuwenden.
Schritt 5. Den Stapel-OCR-Vorgang abschließen
Die Stapel-OCR-Software beginnt nun sofort mit Vorgang. Sie können den Fortschritt auf dem Bildschirm überwachen. Sobald alle von Ihnen hochgeladenen PDF-Dateien erfolgreich verarbeitet wurden, klicken Sie auf den „Fertig“-Knopf. Nun wird der Zielordner geöffnet.
Schritt 6. Bearbeiten Sie die PDF-Dateien nach dem Anwenden von OCR
Super! Nun sind Ihre PDF-Dateien bearbeitbar und durchsuchbar. Öffnen Sie den Ordner, den Sie beim Speichern der Dateien für die OCR-Stapelverarbeitung festgelegt haben und öffnen Sie die Dateien mit PDFelement.
Klicken Sie im Hauptmenü jetzt auf den „Bearbeiten“-Knopf und wählen Sie in den Bearbeitungsoptionen den Zeilenmodus oder Absatzmodus. Springen Sie nun zu dem zu bearbeitenden Absatz, in dem Sie darauf klicken. Mit der Rücktaste können Sie Text löschen, Sie können aber neuen Text, Links und Bilder hinzufügen.
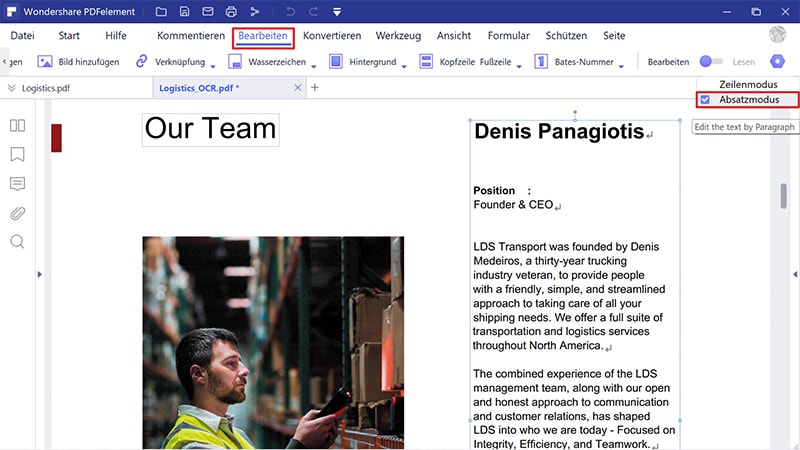
Sobald die Bearbeitung abgeschlossen ist, sollten Sie Ihre PDF-Datei unbedingt speichern!
100% sicher | Werbefrei | Keine MalwareNun, nachdem Sie die leistungsstarke OCR-Stapelverarbeitungsfunktion von PDFelement kennengelernt haben, wollen Sie sicherlich mehr über PDFelement erfahren. Hierbei handelt es sich um ein PDF-Dienstprogramm mit zahlreichen PDF-Funktionen, die vom Erstellen von PDF-Dateien über die Bearbeitung von PDF-Dateien bis zum Austausch von Dateien reichen. Mithilfe der OCR-Funktion können Sie Texte in verschiedenen Sprachen im Stapelmodus scannen und dann im gewünschten Ordner speichern. Weitere Funktionen dieser Software sind:
- Konvertieren von PDF-Dateien in bearbeitbare Ausgabeformate wie Excel, Word, PPT, HTML, Bilder, einfache Texte und EPUB.
- Erstellen von PDF-Dateien aus PDF-Vorlagen, von Scannern, Druckern und aus beliebigen Dateiformaten.
- Bearbeiten von PDF-Inhalten wie Texten, Bildern, Objekten, Links und Seiten.
- Ausfüllen von Formularen, Extrahieren von Daten aus Formularen und Erstellen von Formularen.
- Dateien zu PDF-Dateien zusammenführen.
- Verschlüsseln von PDF-Dateien mithilfe digitaler Signaturen und Wasserzeichen sowie Schwärzungen.
- Teilen von PDF-Dateien mithilfe von E-Mails und Cloud-Speichern.
Wie Sie OCR-PDF-Dateien mit Adobe Acrobat im Stapelmodus verarbeiten
Adobe Acrobat bietet ebenfalls eine Option zur OCR-Stapelverarbeitung, mit der Sie Ihre Arbeit erleichtern können. Der dafür nötige Weg ist einfach und unkompliziert, wenn Sie diese Software gekauft haben. Hier finden Sie eine Anleitung für die OCR-Stapelverarbeitung mit Adobe Acrobat
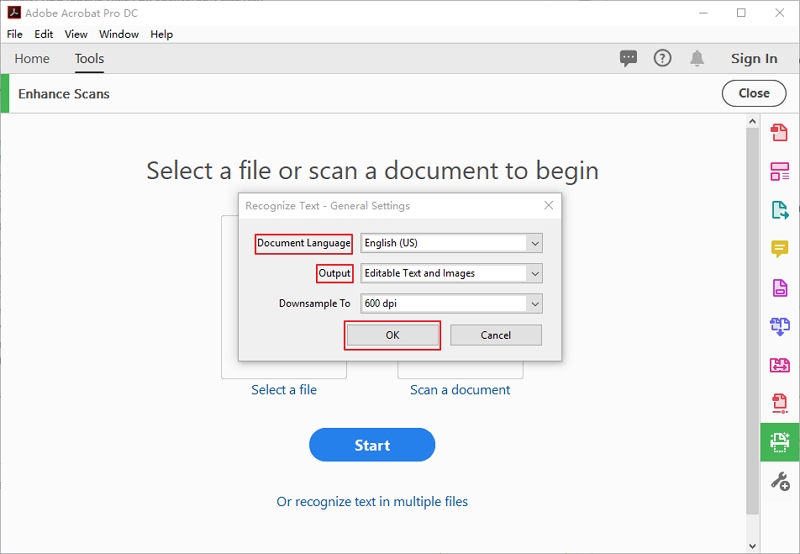
Schritt 1.Laden Sie Adobe Acrobat herunter und installieren Sie es auf Ihrem PC. Öffnen Sie die Software nun und klicken Sie auf die Option „Scans verbessern“.
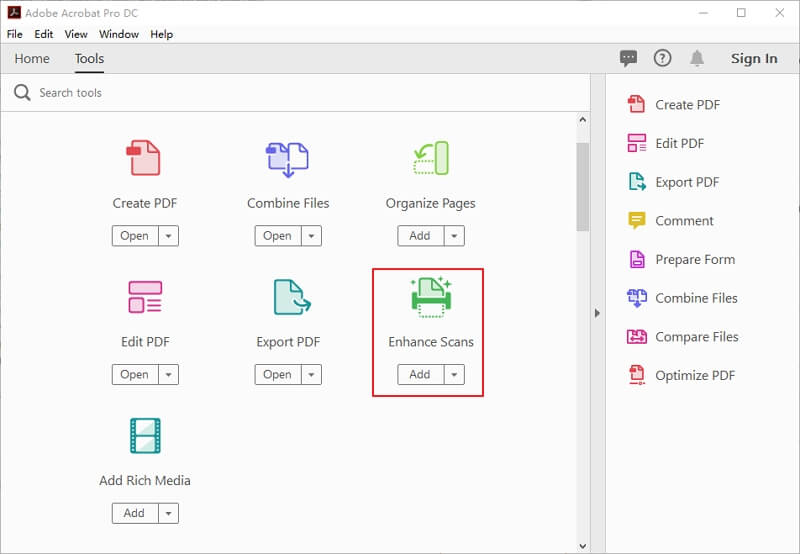
Schritt 2. Klicken Sie nun auf „Text in mehreren Dateien erkennen“. Jetzt können Sie Dateien zu Adobe Acrobat hinzufügen.
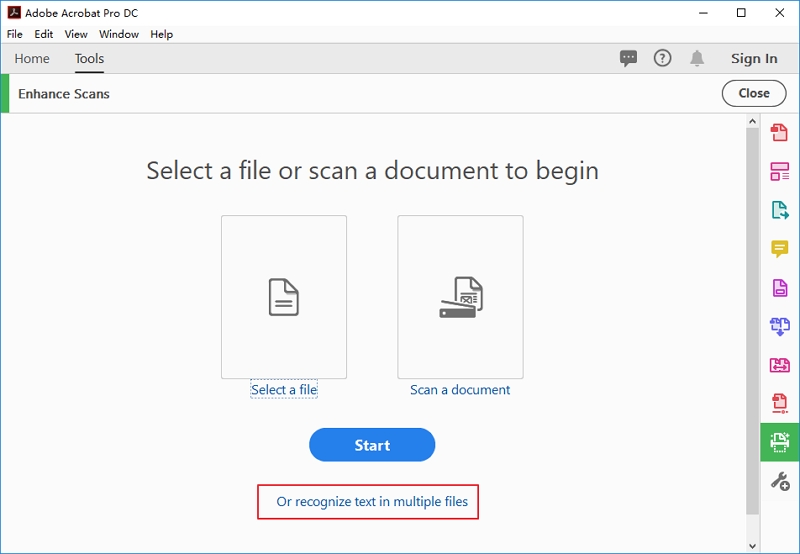
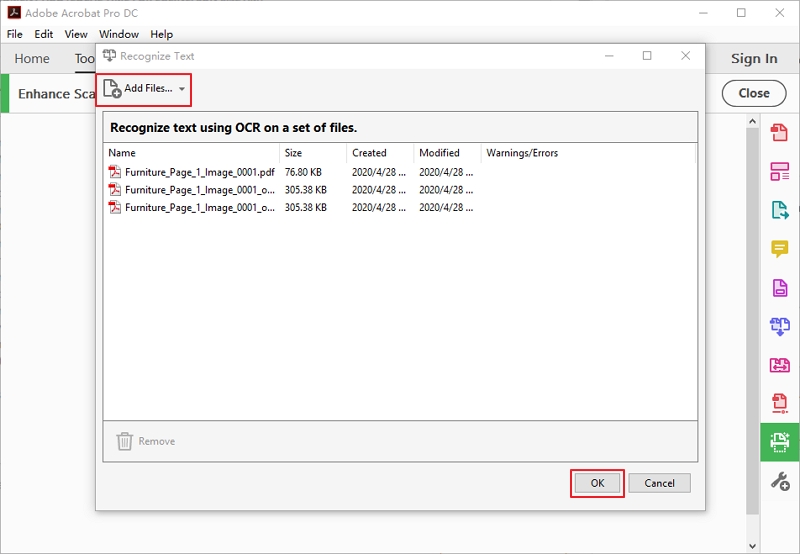
Schritt 3.Nun erscheint ein Dialogfenster, in dem Sie mehrere Dateien hinzufügen können. Klicken Sie auf „Dateien hinzufügen“ und wählen Sie die gewünschten PDF-Dateien. Klicken Sie nach dem Hochladen auf den „OK“-Knopf.
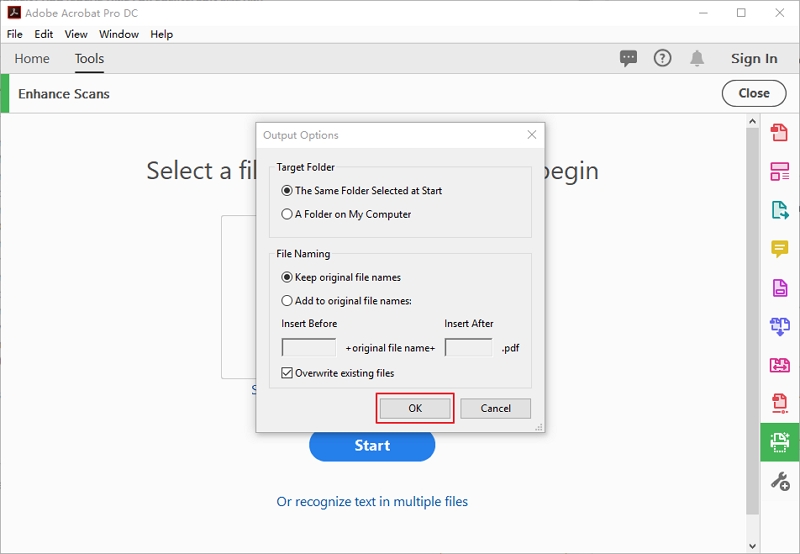
Schritt 4.Nun müssen Sie die Ausgabeeinstellungen festlegen. Wählen Sie den „Zielordner“ und geben Sie den „Dateinamen“ ein. Legen Sie außerdem fest, ob Sie Ihre „Bestehende Dateien überschreiben“ wollen.
Schritt 5.Wählen Sie abschließend die OCR-Sprache, je nach der Textsprache Ihrer OCR-Dateien. Wählen Sie schließlich die Ausgabeoptionen und klicken Sie auf „OK“, um die OCR-Stapelverarbeitung in Adobe abzuschließen. Klicken Sie nun auf „Start“, um OCR im Stapelmodus auf Dateien in Adobe Acrobat anzuwenden.