Text aus gescannten PDFs kopieren
Einfache Textextraktion aus gescannten Dokumenten. Präzise & Schnell
- Kopieren Sie Text aus gescannten PDFs mit fortschrittlicher OCR-Technologie
- Erkennen Sie Text in über 20 Sprachen mit hoher Genauigkeit
- Bewahren Sie die ursprüngliche Formatierung beim Kopieren
- Einfache Bedienung für schnelle Ergebnisse

2025-05-21 17:37:42 • Abgelegt unter: PDFelement How-Tos • Bewährte Lösungen
4 Methoden zum Kopieren vom Text aus gescannter PDF
Das Kopieren von Texten aus gescannten PDFs ist ohne ein OCR-Tool eine nahezu unmögliche Aufgabe. Glücklicherweise gibt es mehrere OCR-Tools, doch die Suche nach dem passenden Tool zum Kopieren von Text aus einem gescannten Dokument kann sich oftmals als recht mühsam erweisen. Wenn Sie erfolglos danach gesucht haben, wie Sie Text aus einem gescannten PDF kopieren können, dann sollte dieser Artikel genau richtig für Sie sein. In dieser Anleitung zeigen wir Ihnen, wie Sie Text aus einer gescannten PDF-Datei kopieren können.
 G2-Wertung: 4.5/5 |
G2-Wertung: 4.5/5 |  100 % Sicher |
100 % Sicher |
 G2-Wertung: 4.5/5 |100 % Sicher |
G2-Wertung: 4.5/5 |100 % Sicher |- Teil 1. 2 Methoden, Text aus gescannter PDF offline zu kopieren
- Teil 2. 2 Methoden, Text aus gescannter PDF online zu kopieren
- Teil 3. Tipps zum Kopieren vom Text aus gescannten PDF
- Teil 4. So kopieren Sie Text aus einer geschützten PDF
- Teil 5. So kopieren Sie Text von Bild
- FAQs zum Kopieren vom Text aus gescannten PDF
Teil 1. 2 Methoden, Text aus gescannter PDF offline zu kopieren
Das Kopieren von Text aus gescannten PDF-Dateien kann eine Herausforderung sein, da der Text in diesen Dateien normalerweise als Bild gespeichert wird. Hier sind vier Methoden, die Ihnen dabei helfen können, Text aus gescannten PDF-Dateien zu kopieren.
Methode 1: So kopieren Sie Text aus einer gescannten PDF-Datei mit Wondershare PDFelement
Wondershare PDFelement - PDF Editor ist eine leistungsstarke und vollständige PDF-Lösung, die von Millionen von Menschen auf der ganzen Welt genutzt wird. Das Programm verfügt über eine Vielzahl hervorragender Funktionen, die es ideal für alle Arten von Aufgaben und Organisationen machen. Das Programm ermöglicht es Anwendern, ihre PDF-Dokumente auf einer einzigen Plattform zu konvertieren, zu bearbeiten, mit Kommentaren zu versehen, zu drucken, zu organisieren, zu betrachten, zu erstellen, OCR durchzuführen, zu schützen und zu teilen.
Schritt 1. Ihre gescannte PDF-Datei mit PDFelement öffnen
Öffnen Sie PDFelement auf Ihrem Computer und navigieren Sie zur Hauptansicht. Klicken Sie unten links auf "PDF öffnen" oder das Symbol "+". Sie werden zum Datei-Explorer-Fenster weitergeleitet, in dem Sie die gescannte pdf-Datei auswählen, deren Texte Sie kopieren möchten. Markieren Sie die gescannte PDF-Zieldatei und klicken Sie auf "Öffnen", um sie hochzuladen.
G2-Wertung: 4.5/5 | 100 % Sicher | G2-Wertung: 4.5/5 |100 % Sicher |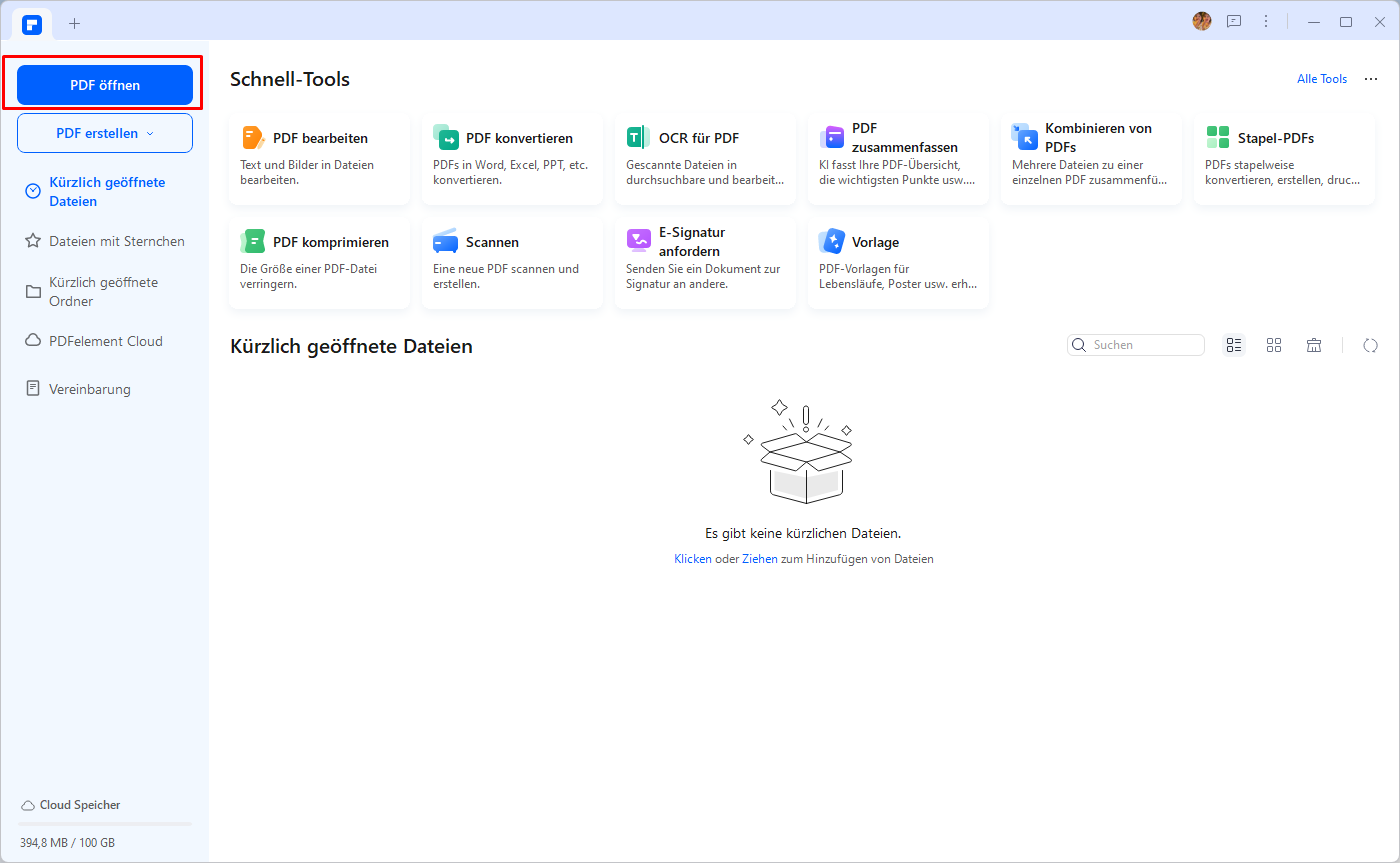
Schritt 2. OCR-Komponente herunterladen und PDF-Datei scannen
Nach dem Hochladen erkennt das Programm automatisch, dass Sie eine gescannte PDF-Datei hochgeladen haben und empfiehlt Ihnen, ein OCR durchzuführen. Klicken Sie auf "OCR" und dann im kleinen Fenster auf die Schaltfläche "Herunterladen" unter "OCR-Komponente herunterladen".
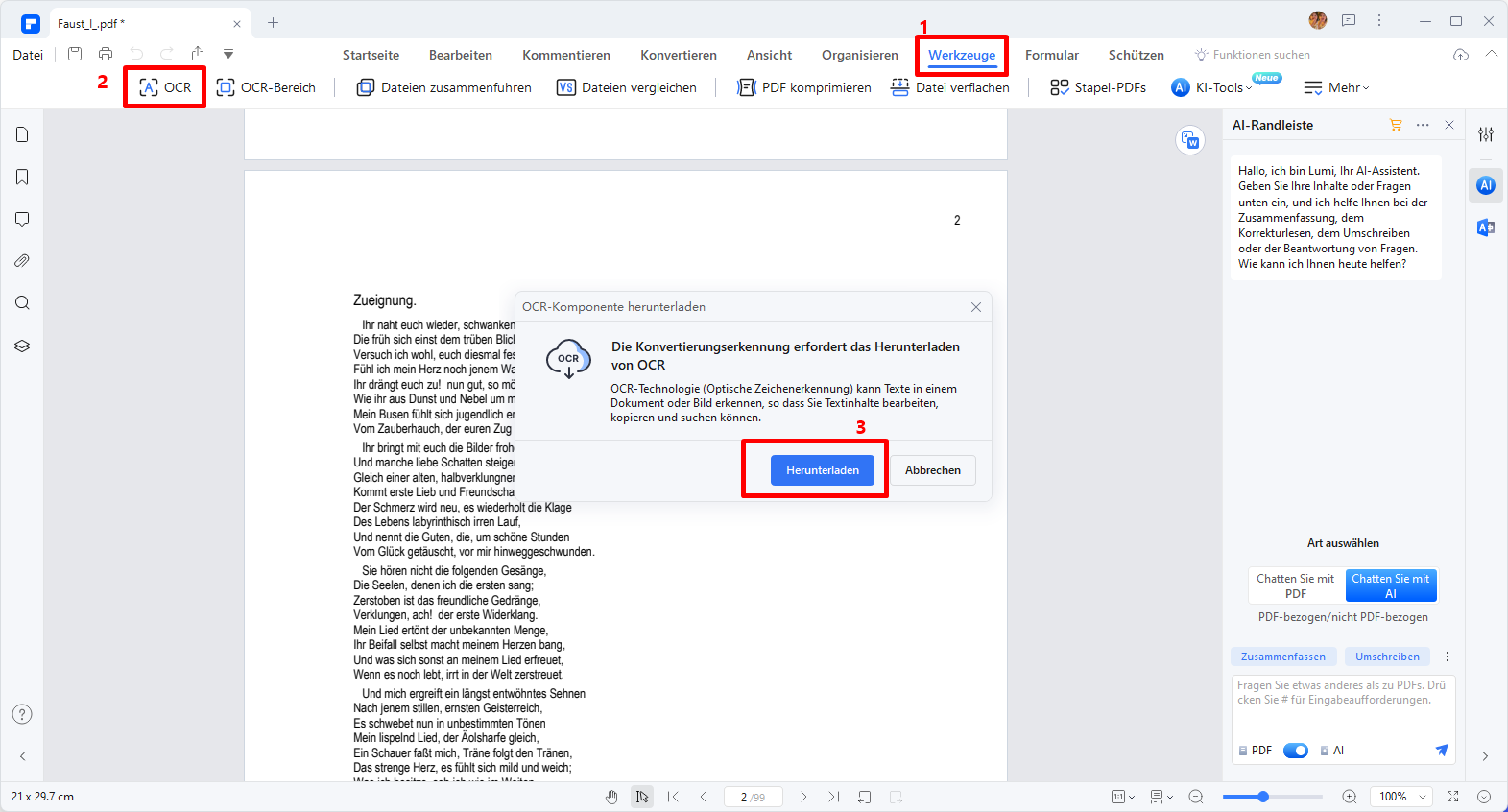
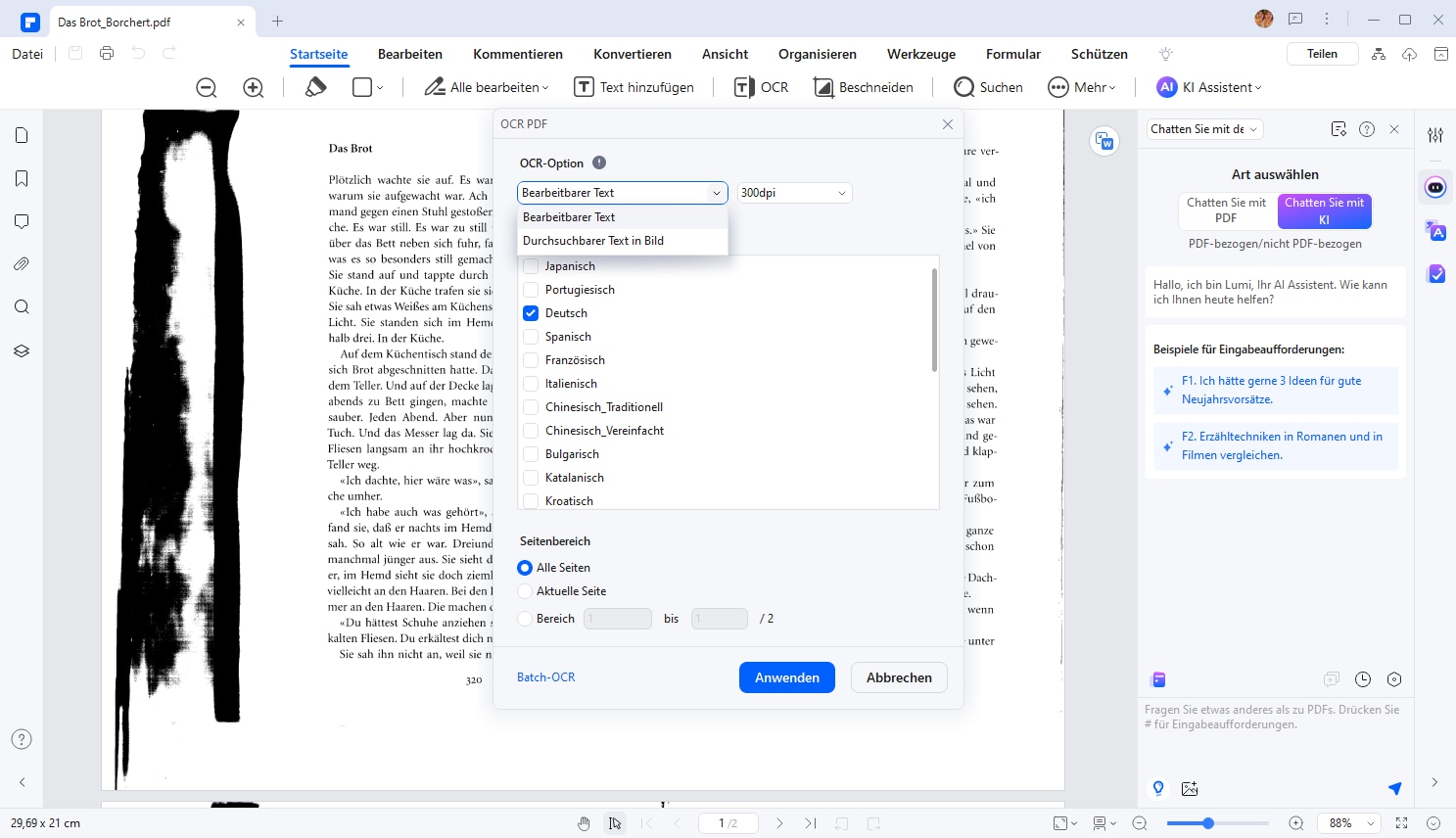
Nachdem Sie die OCR-Komponente heruntergeladen haben, gehen Sie auf die Registerkarte "Werkzeug" und wählen Sie "OCR" aus dem Untermenü. Klicken Sie erneut auf den Link "OCR ausführen" in der Benachrichtigung unterhalb der Menüleiste. Daraufhin öffnet sich das Fenster "OCR PDF", in dem Sie "Bearbeitbarer Text" auswählen können. Klicken Sie danach auf die Schaltfläche "Anwenden", um die Datei in bearbeitbaren Text umzuwandeln.
 G2-Wertung: 4.5/5 | 100 % Sicher | G2-Wertung: 4.5/5 |100 % Sicher |
G2-Wertung: 4.5/5 | 100 % Sicher | G2-Wertung: 4.5/5 |100 % Sicher |Schritt 3. Text aus gescannter PDF kopieren
Klicken Sie oben rechts im Fenster auf die Cursorschaltfläche unten, um in den „Auswahlmodus“ zu wechseln. Wählen Sie dann den Text in der PDF-Datei aus und klicken Sie mit der rechten Maustaste darauf. Wählen Sie „Text kopieren“, um die Zieltexte aus der gescannten PDF-Datei zu kopieren.
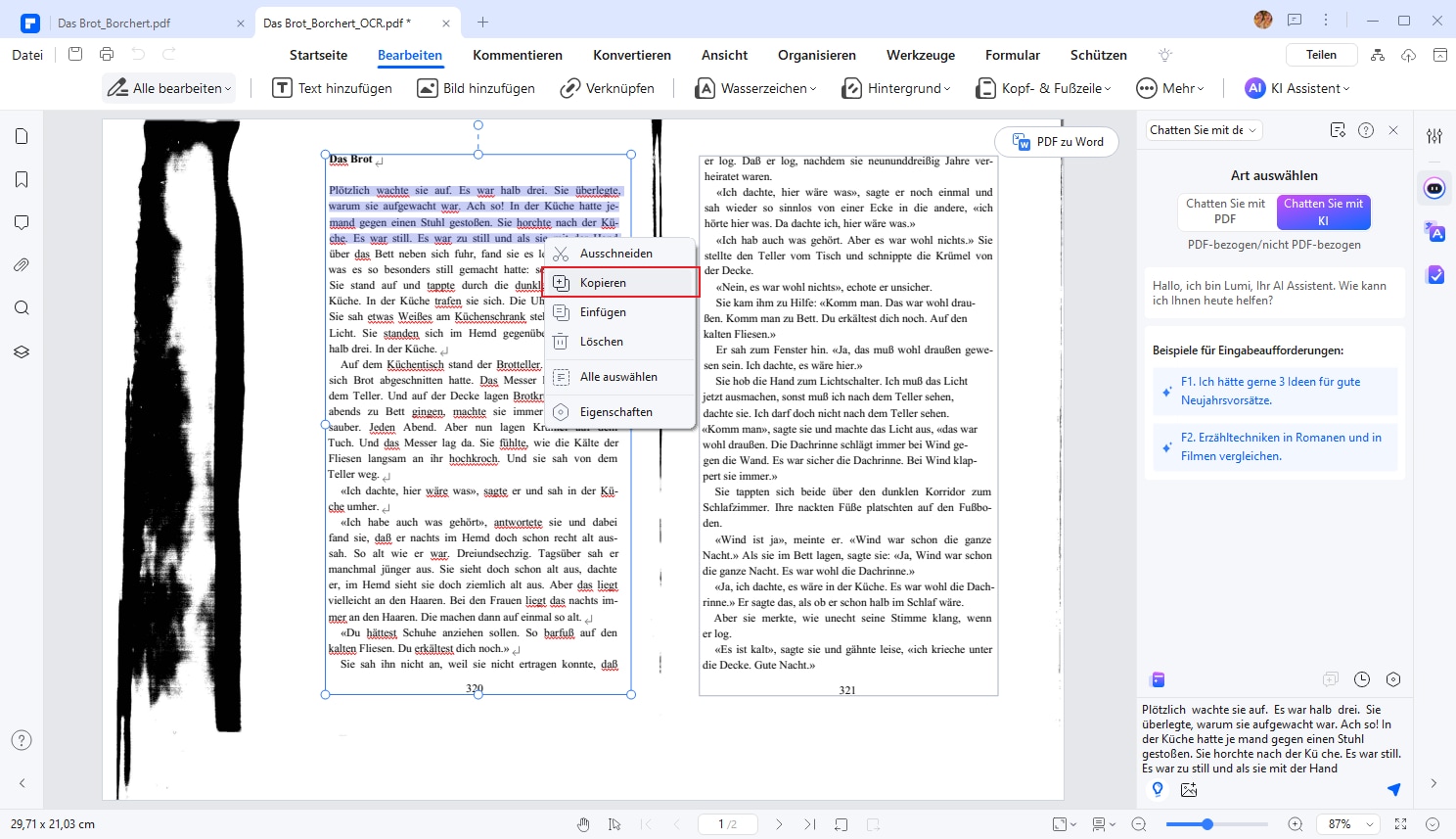
Tipp: Vor- und Nachteile der OCR-Funktion in Wondershare PDFelement
Vorteile:
- Texterkennung in gescannten Dokumenten: Die OCR-Funktion ermöglicht es Ihnen, Text in gescannten Dokumenten zu erkennen und in bearbeitbaren Text umzuwandeln. Dadurch können Sie den Text in Ihren PDF-Dateien durchsuchen, kopieren und bearbeiten.
- Erhaltung des Originalformats: Die OCR-Funktion von PDFelement versucht, das ursprüngliche Layout und Format des gescannten Dokuments beizubehalten. Dadurch bleibt die Struktur des Dokuments intakt und Sie können es leichter lesen und verstehen.
- Mehrsprachige Unterstützung: Die OCR-Funktion von PDFelement unterstützt eine Vielzahl von Sprachen, sodass Sie gescannte Dokumente in verschiedenen Sprachen erkennen und bearbeiten können.
- Zeitersparnis: Durch die automatische Texterkennung sparen Sie Zeit, da Sie nicht mehr den gesamten Text manuell abtippen müssen. Die OCR-Funktion erledigt diese Aufgabe für Sie und ermöglicht es Ihnen, den Text schnell zu bearbeiten oder zu extrahieren.
- Verbesserte Produktivität: Mit der OCR-Funktion können Sie gescannte Dokumente in durchsuchbare und bearbeitbare PDFs umwandeln. Dadurch können Sie effizienter arbeiten und Informationen schneller finden.
Nachteile:
- Genauigkeit der Texterkennung: Die OCR-Technologie ist nicht perfekt und kann gelegentlich Fehler bei der Texterkennung machen. Dies kann zu falsch erkannten Wörtern oder ungenauen Formatierungen führen.
- Abhängigkeit von der Qualität des gescannten Dokuments: Die Genauigkeit der OCR-Funktion hängt stark von der Qualität des gescannten Dokuments ab. Wenn das Dokument unscharf oder von schlechter Qualität ist, kann die Texterkennung beeinträchtigt werden.
Glücklicherweise kann Ihnen die neue KI-Funktion von PDFelement dabei helfen, Texte einfach und effizient Korrektur zu lesen.
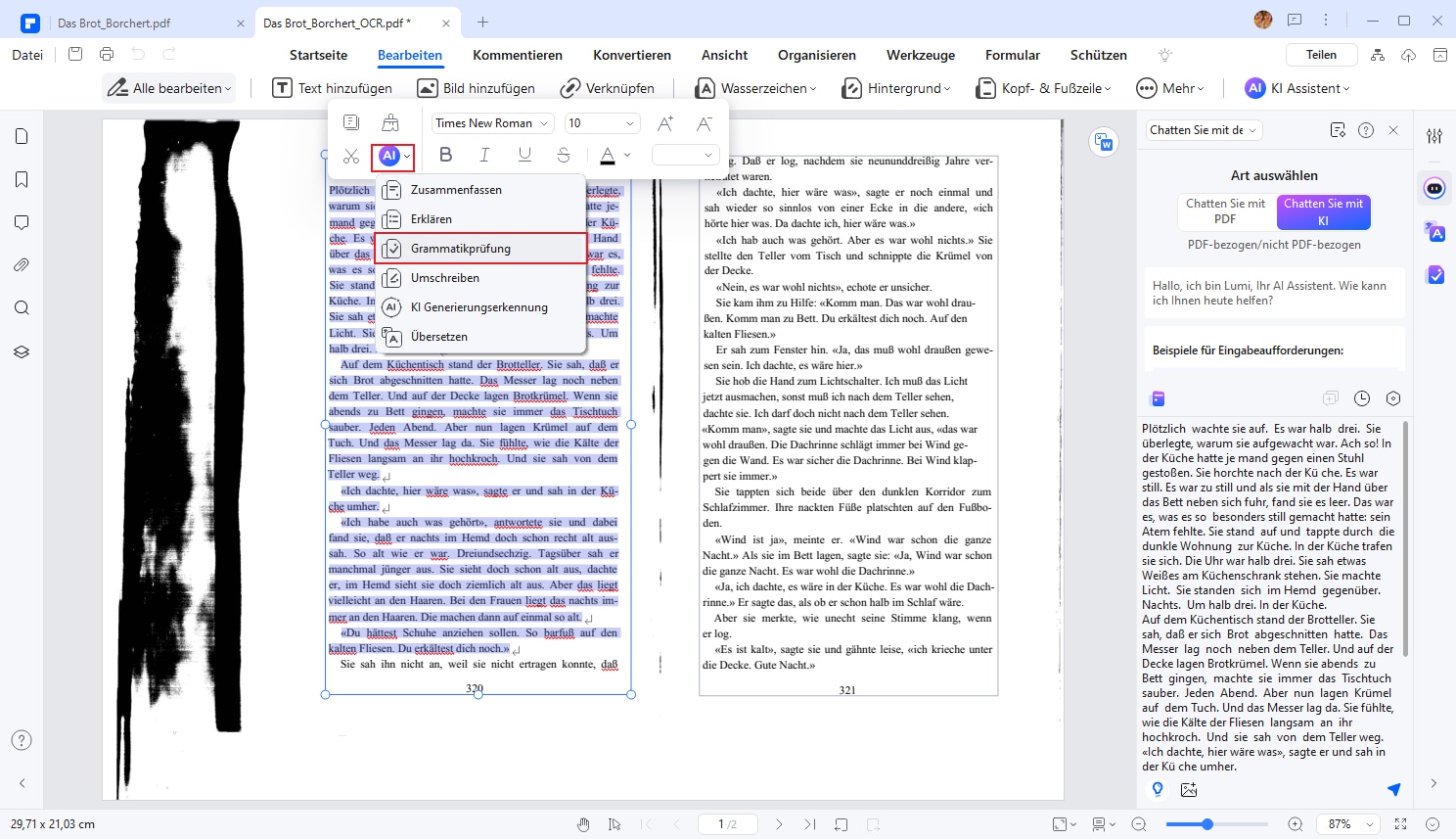
Video Tutorial: So führen Sie OCR in PDF aus - gescanntes Bild in bearbeitbaren Text konvertieren
G2-Wertung: 4.5/5 | 100 % Sicher |
G2-Wertung: 4.5/5 |100 % Sicher |Methode 2: So kopieren Sie Text aus einer gescannten PDF-Datei mit Wondershare PDF Converter Pro
Wondershare PDF Converter Pro ist ein preiswerter und hoch bewerteter PDF-Konverter. Er unterstützt die Konvertierung von PDF in und aus anderen Formaten, darunter Word, Excel, PPT, Bildformate und so weiter. Mit Wondershare Converter Pro können Sie ganz einfach PDFs erstellen, bearbeiten, signieren, komprimieren, OCR durchführen und mehrere PDFs zusammenführen.
Schritt 1. PDF-Datei hinzufügen
Öffnen Sie Wondershare Converter Pro und klicken Sie dann auf die Schaltfläche "Add" ("Hinzufügen"). Suchen Sie nach der gescannten PDF-Datei und klicken Sie dann auf die Schaltfläche "Open" ("Öffnen"), um die Datei in die Oberfläche von Wondershare Converter Pro zu importieren. Alternativ können Sie auch die Drag-and-Drop-Methode verwenden.
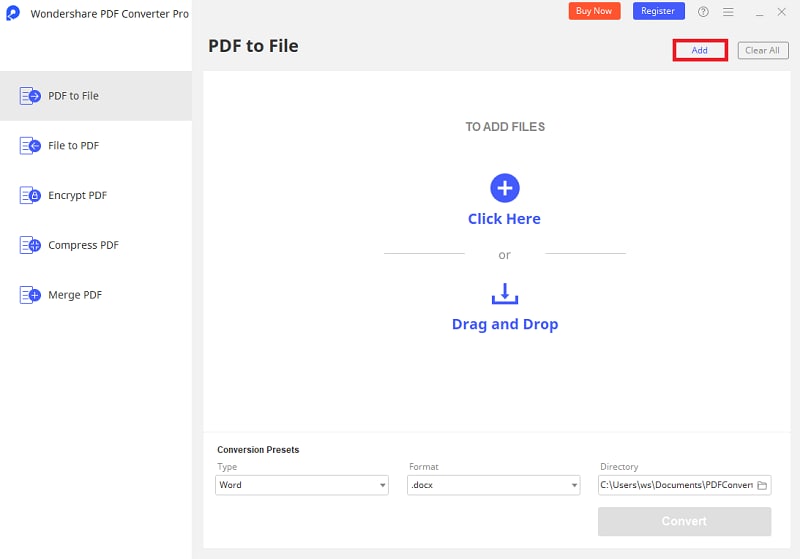
Schritt 2. OCR einschalten
Klicken Sie auf den Tab "PDF to File" ("PDF zu Datei") und dann auf die Schaltfläche "Convert" ("Konvertieren") am unteren Rand. Das Programm schlägt automatisch vor, dass Sie eine OCR an der Datei durchführen. Klicken Sie auf "OCR versuchen", um das Fenster "OCR Settings" ("OCR-Einstellungen") zu öffnen. Wählen Sie Ihre gewünschte Sprache und klicken Sie auf die Schaltfläche "Submit" ("Senden").

Schritt 3. PDF in Word konvertieren
Sobald der OCR-Vorgang abgeschlossen ist, klicken Sie auf die Registerkarte "PDF zu Datei", wählen Sie Word als Ausgabeformat. Klicken Sie auf "Konvertieren", um die Konvertierung auszulösen. Wenn die Konvertierung abgeschlossen ist, suchen Sie die Datei und kopieren Sie den gewünschten Inhalt.
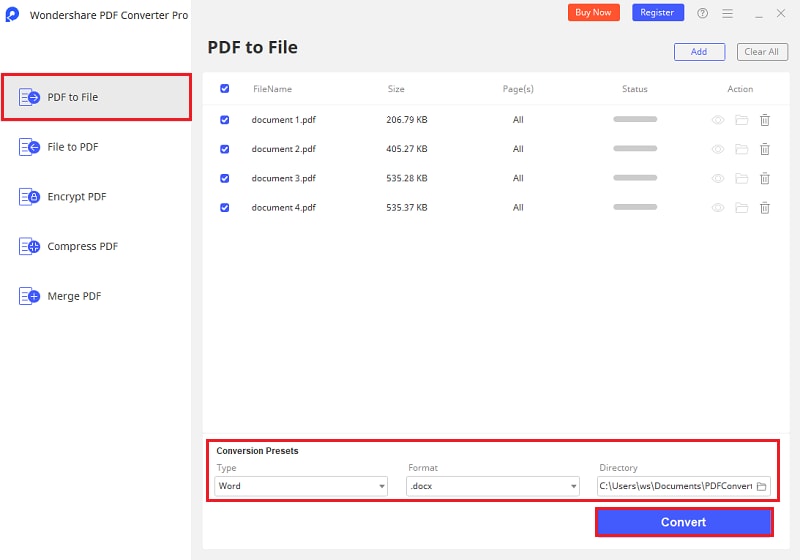
Teil 2. 2 Methoden, Text aus gescannter PDF online zu kopieren
Methode 3: Kopieren von Text aus gescannter PDF in Google Drive
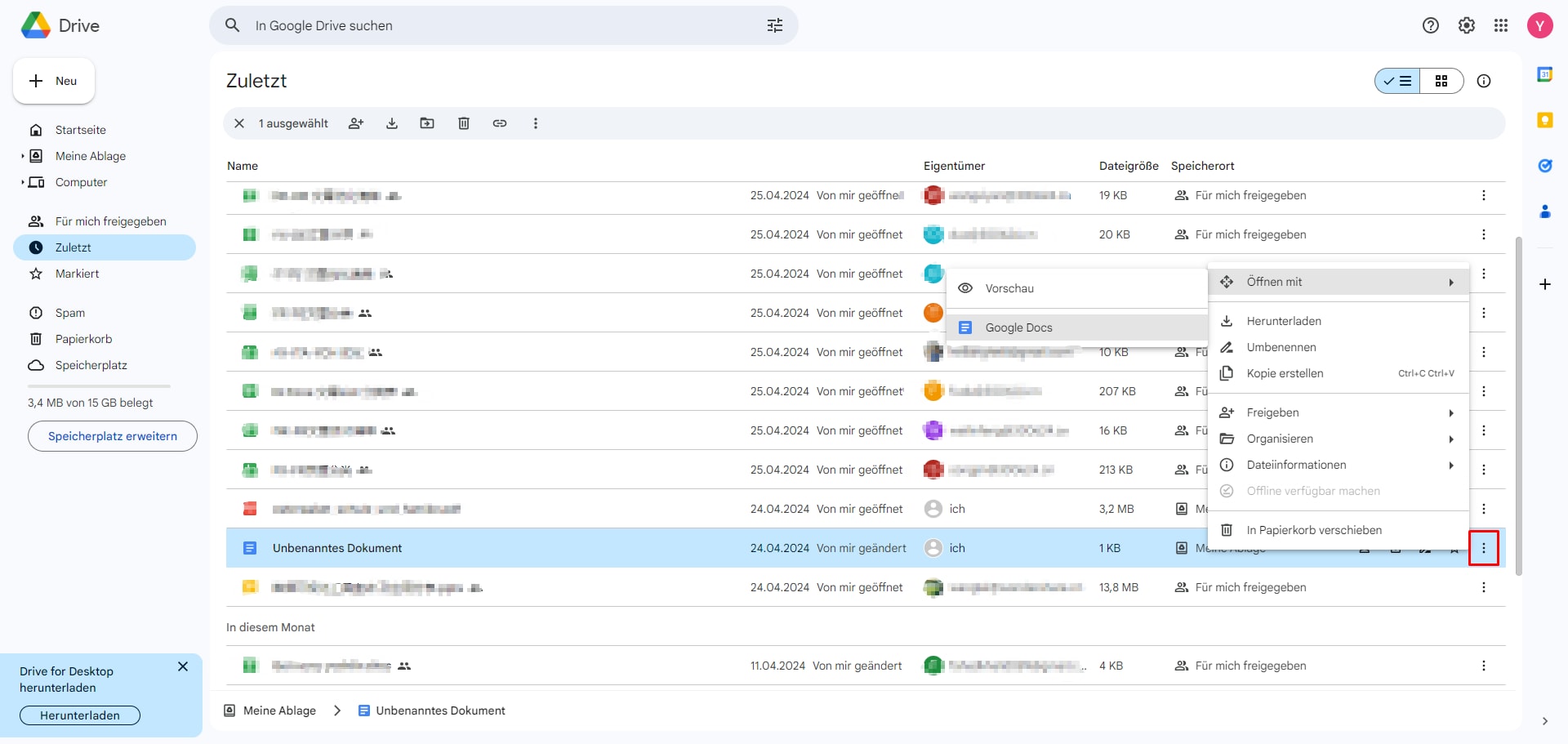
Schritt 1. Navigieren Sie zu Google Drive.
Schritt 2. Laden Sie Ihre gescannte PDF-Datei hoch, klicken Sie mit der rechten Maustaste auf die PDF-Datei, die Sie kopieren möchten, und gehen Sie dann auf "Öffnen mit" > "Google Docs". Nun wird die PDF-Datei automatisch in Google Docs geöffnet.
Schritt 3. Nachdem Ihre PDF-Datei in Google Doc konvertiert wurde, können Sie problemlos Text aus einer gescannten PDF-Datei kopieren.
Methode 4: So kopieren Sie Text aus gescanntem PDF mit HiPDF
HiPDF ist ein hervorragendes Online-PDF-Konvertierungstool, das auch die OCR-Funktion unterstützt. Es hat eine benutzerfreundliche Oberfläche und einen einfachen Konvertierungsprozess. Die folgenden Schritte zeigen, wie Sie mit HiPDF Text aus gescannten PDFs kopieren können.
Schritt 1. Besuchen Sie die hiPDF OCR-Seite mit Ihrem Browser und melden Sie sich an.
Schritt 2. Als Nächstes gehen Sie auf die Schaltfläche "DATEI WÄHLEN", um die gescannte PDF-Datei hochzuladen. Sie können die Datei stattdessen auch per Drag & Drop auf die Benutzeroberfläche ziehen.
Schritt 3. Wenn die gescannte Datei hochgeladen wird, erkennt das Programm automatisch und fordert Sie auf, die OCR durchzuführen. Akzeptieren Sie die Aufforderung, um das Fenster "OCR"-Einstellungen aufzurufen. Wählen Sie die richtige Sprache und wählen Sie "Docx" als Ausgabeformat. Klicken Sie auf "Senden", um die OCR auszulösen. Wenn die OCR abgeschlossen ist, können Sie nun Ihre Texte kopieren.

Teil 3. Tipps zum Kopieren vom Text aus gescannten PDF
Das Kopieren von Text aus gescannten PDF-Dateien kann eine Herausforderung sein, da der Text in diesen Dateien normalerweise als Bild gespeichert wird. Hier sind einige Tipps, die Ihnen helfen können, Text aus gescannten PDF-Dateien zu kopieren:
- Verwenden Sie OCR-Software: OCR (Optical Character Recognition) ist eine Technologie, die es ermöglicht, Text aus gescannten Dokumenten zu extrahieren. Verwenden Sie eine OCR-Software wie PDFelement oder Adobe Acrobat, um den Text aus der gescannten PDF-Datei zu extrahieren. Diese Softwareprogramme können den Text erkennen und in bearbeitbaren Text umwandeln, den Sie kopieren und in andere Anwendungen einfügen können.
- Überprüfen Sie die OCR-Ergebnisse: Nachdem Sie die OCR-Software verwendet haben, um den Text zu extrahieren, überprüfen Sie das Ergebnis sorgfältig. Manchmal kann die OCR-Software Fehler machen oder den Text nicht korrekt erkennen. Korrigieren Sie eventuelle Fehler manuell, um sicherzustellen, dass der kopierte Text korrekt ist.
- Verwenden Sie Online-OCR-Dienste: Es gibt auch viele Online-OCR-Dienste, die Sie kostenlos oder gegen eine Gebühr nutzen können. Laden Sie die gescannte PDF-Datei auf die Website hoch und lassen Sie den Dienst den Text extrahieren. Einige Beispiele für Online-OCR-Dienste sind OnlineOCR.net, OCR.space und FreeOCR. Beachten Sie jedoch, dass bei der Verwendung von Online-Diensten Ihre Daten möglicherweise auf externen Servern gespeichert werden. Aus Gründen Ihrer Datensicherheit empfehlen wir Ihnen daher weiterhin, Offline-Software zu verwenden.
- Verbessern Sie die Qualität der gescannten PDF-Datei: Wenn die gescannte PDF-Datei von schlechter Qualität ist, kann dies die Genauigkeit der OCR beeinträchtigen. Versuchen Sie, die Qualität des gescannten Dokuments zu verbessern, indem Sie es erneut scannen oder die Einstellungen des Scanners anpassen. Stellen Sie sicher, dass das Dokument gut beleuchtet und klar ist, um bessere OCR-Ergebnisse zu erzielen.
- Manuelle Eingabe: Wenn keine der oben genannten Methoden funktioniert oder der Text zu komplex ist, um von der OCR-Software erkannt zu werden, müssen Sie den Text möglicherweise manuell eingeben. Öffnen Sie die gescannte PDF-Datei in einem PDF-Viewer und verwenden Sie die Funktion "Text hinzufügen", um den Text manuell einzugeben. Diese Methode ist zeitaufwändig, aber es ist eine Möglichkeit, den Text aus gescannten PDF-Dateien zu kopieren, wenn keine andere Option verfügbar ist.
G2-Wertung: 4.5/5 | 100 % Sicher |
G2-Wertung: 4.5/5 |100 % Sicher |Es ist wichtig zu beachten, dass die Genauigkeit der Texterkennung von der Qualität der gescannten PDF-Datei abhängt. Je besser die Qualität des gescannten Dokuments ist, desto genauer wird die OCR sein.
Teil 4. So kopieren Sie Text aus einer geschützten PDF
Wenn ein PDF-Dokument durch Passwörter oder Einschränkungen geschützt ist, kann das Kopieren von Text eine Herausforderung sein. Hier ist eine Anleitung, wie Sie Text aus einem geschützten PDF mit Wondershare PDFelement kopieren können:
G2-Wertung: 4.5/5 | 100 % Sicher |
G2-Wertung: 4.5/5 |100 % Sicher |Schritt 1: Öffnen Sie das geschützte PDF in Wondershare PDFelement, indem Sie die Software starten und auf "Datei öffnen" klicken. Navigieren Sie zu dem Speicherort der PDF-Datei und wählen Sie sie aus.
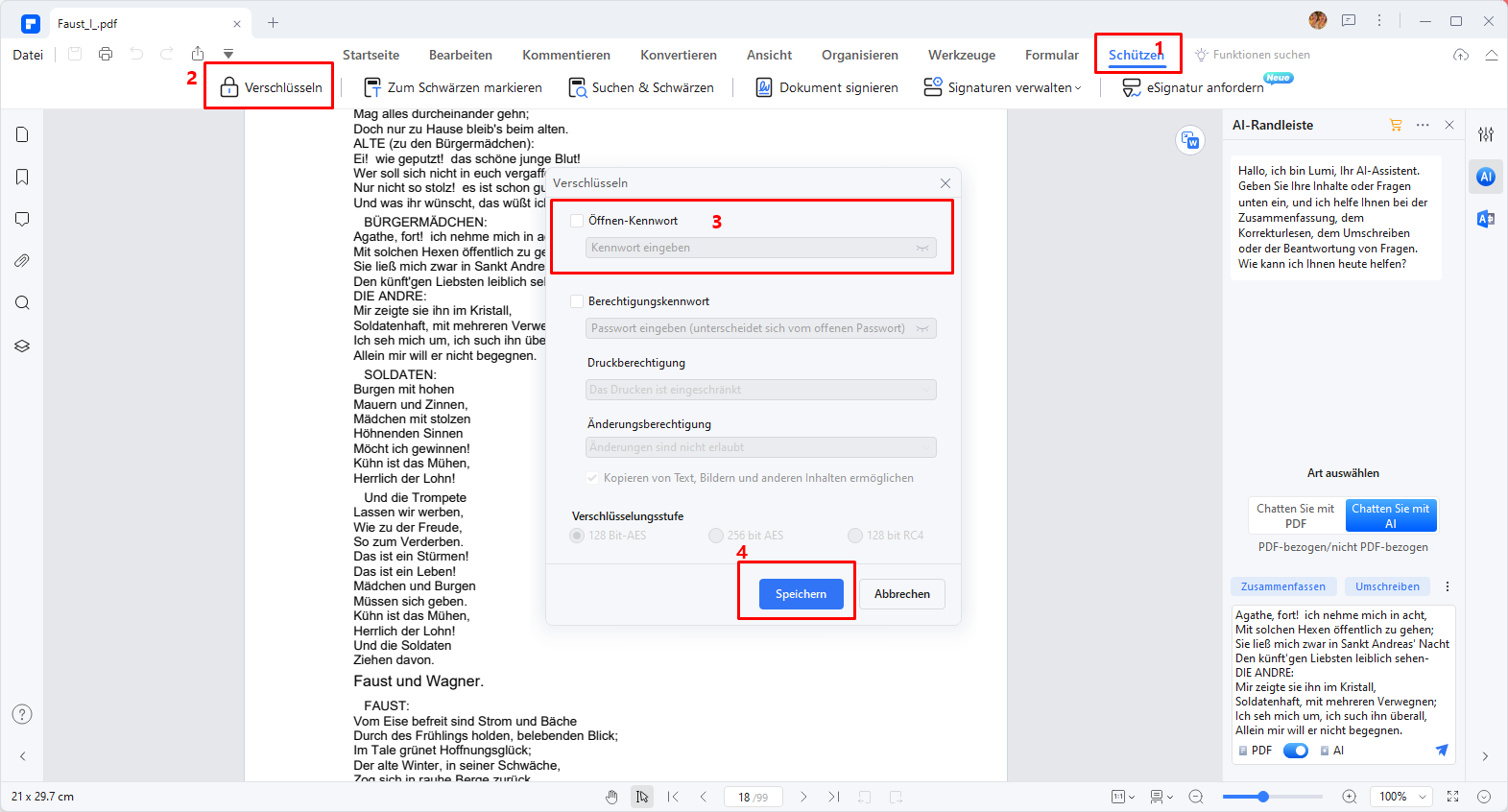
Schritt 2: Klicken Sie auf „Schützen“ > „Verschlüsseln“, deaktivieren Sie dann „Öffnen-Kennwort“ und klicken Sie auf „Speichern“, um mit der PDF-Bearbeitung problemlos zu beginnen.
Schritt 3: Sobald das PDF geöffnet ist, können Sie den Text auswählen und kopieren. Klicken Sie dann mit der rechten Maustaste auf den ausgewählten Text und wählen Sie "Kopieren" aus dem Kontextmenü.
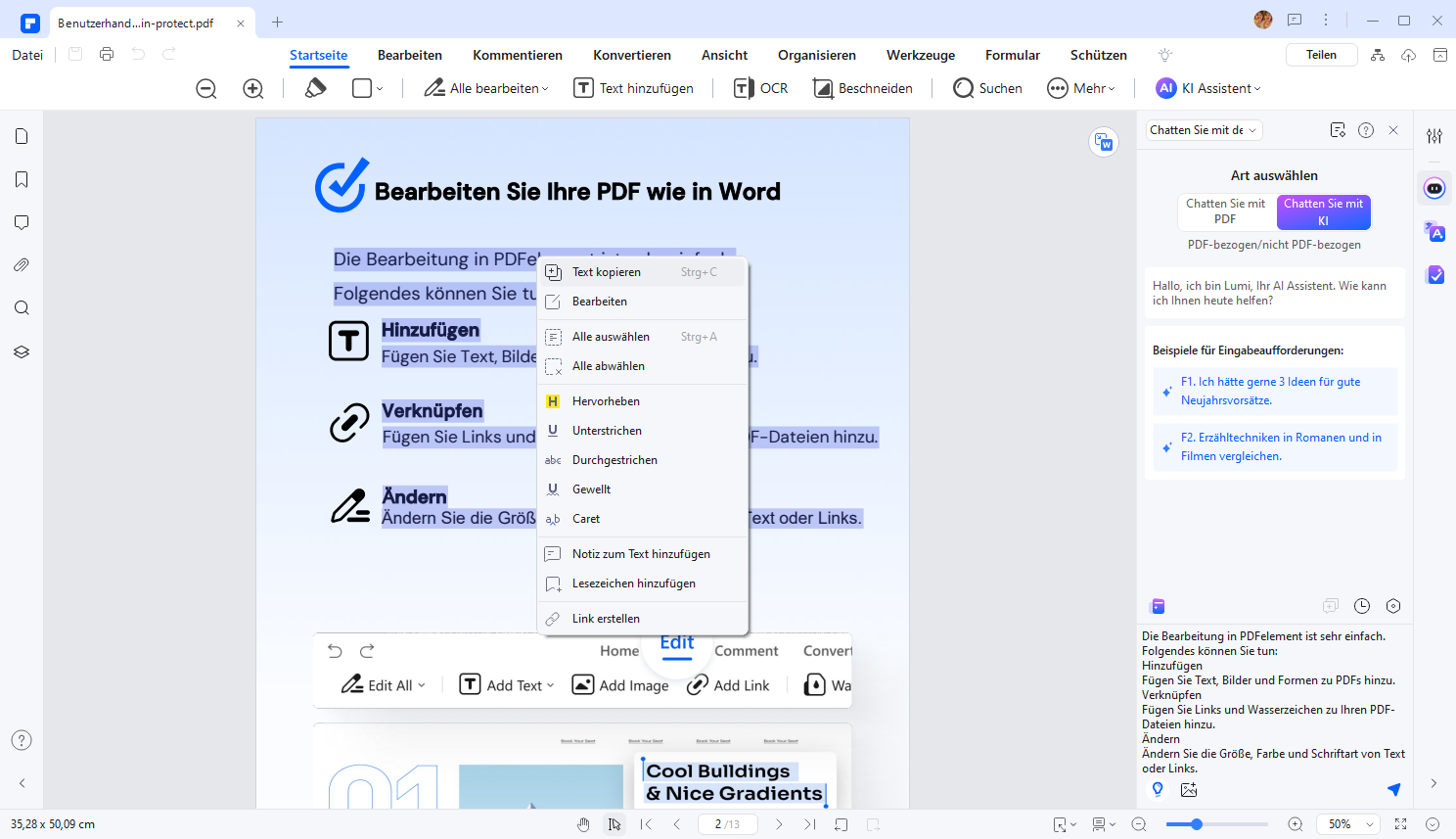
Bitte beachten Sie, dass das Umgehen von Passwörtern oder Einschränkungen in geschützten PDF-Dateien möglicherweise gegen die Nutzungsbedingungen oder das Urheberrecht verstößt. Stellen Sie sicher, dass Sie berechtigt sind, den Text aus dem PDF zu kopieren, bevor Sie diese Schritte ausführen.
Teil 5. So kopieren Sie Text von Bild
Manchmal möchten Sie Text direkt von einem Bild extrahieren. Mit PDFelement können Sie Text von Bildern leicht kopieren und in ein editierbares Dokument umwandeln. Hier ist eine Schritt-für-Schritt-Anleitung:
G2-Wertung: 4.5/5 | 100 % Sicher |
G2-Wertung: 4.5/5 |100 % Sicher |Schritt 1: Öffnen Sie das Bild
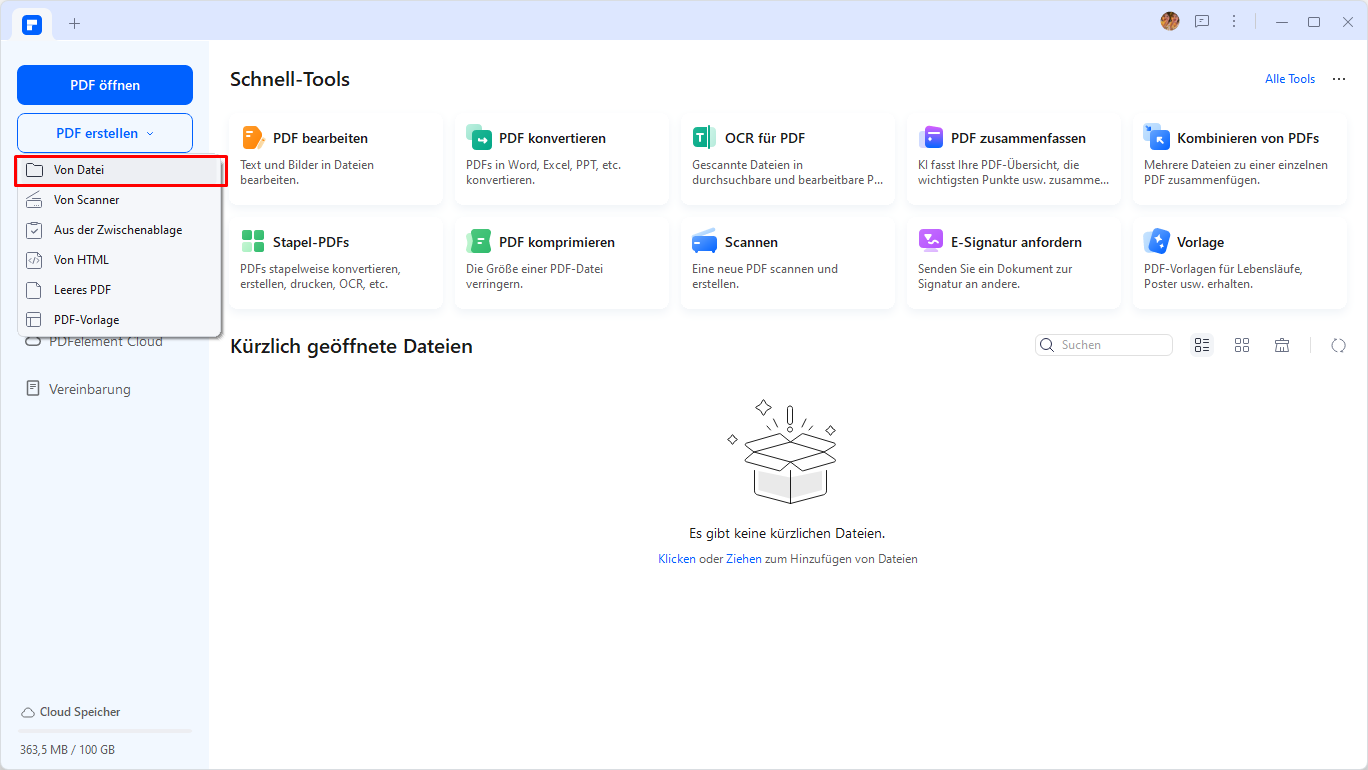
Öffnen Sie das Bild, von dem Sie den Text kopieren möchten, in PDFelement. Klicken Sie auf "PDF erstellen" > "Von Datei".
Schritt 2: Wählen Sie die OCR-Funktion
Wenn Sie ein Bild direkt importieren, erscheint in der blauen Leiste oben „OCR ausführen“. Klicken Sie darauf und speichern Sie das Bild zunächst als PDF.
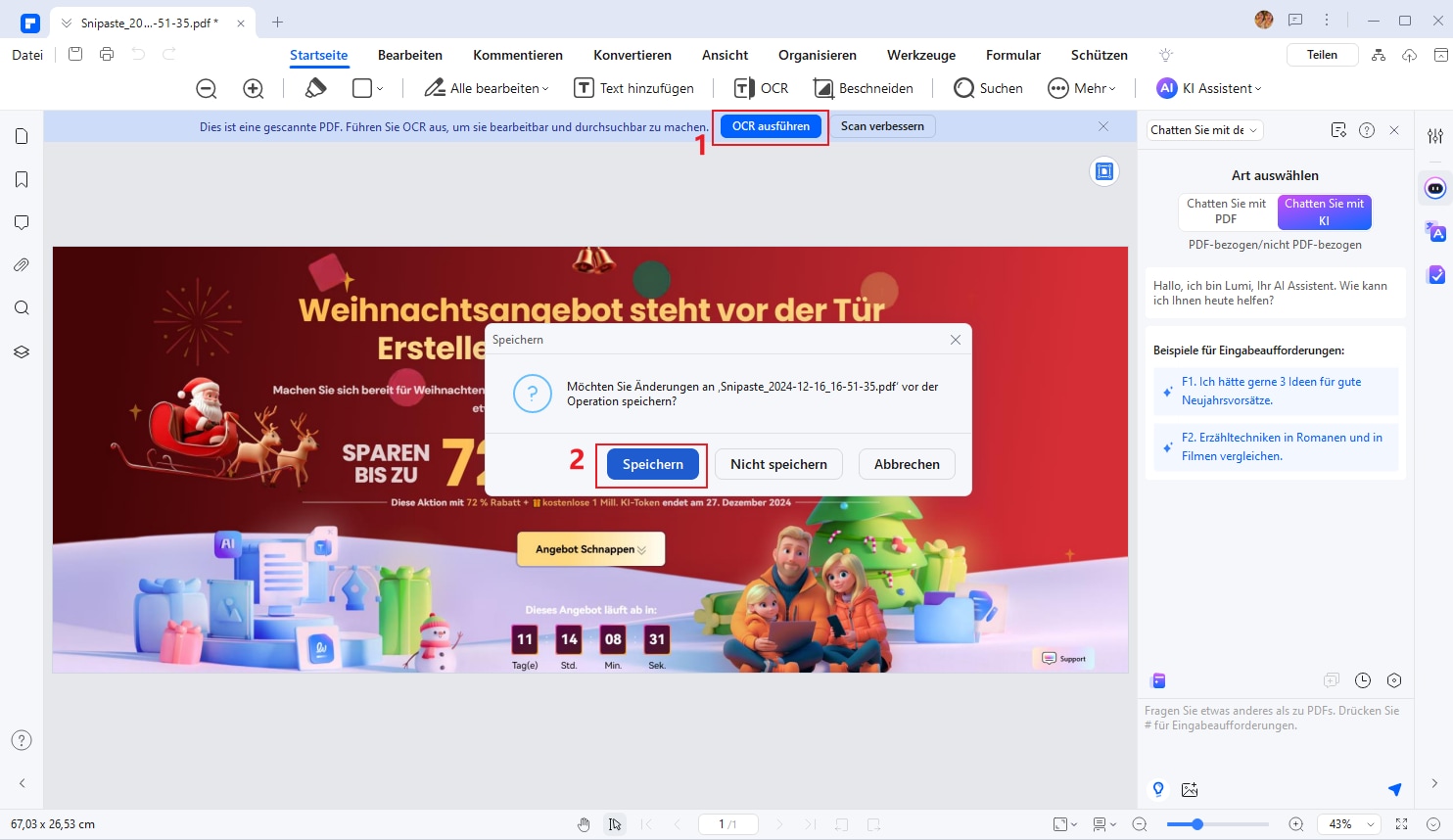
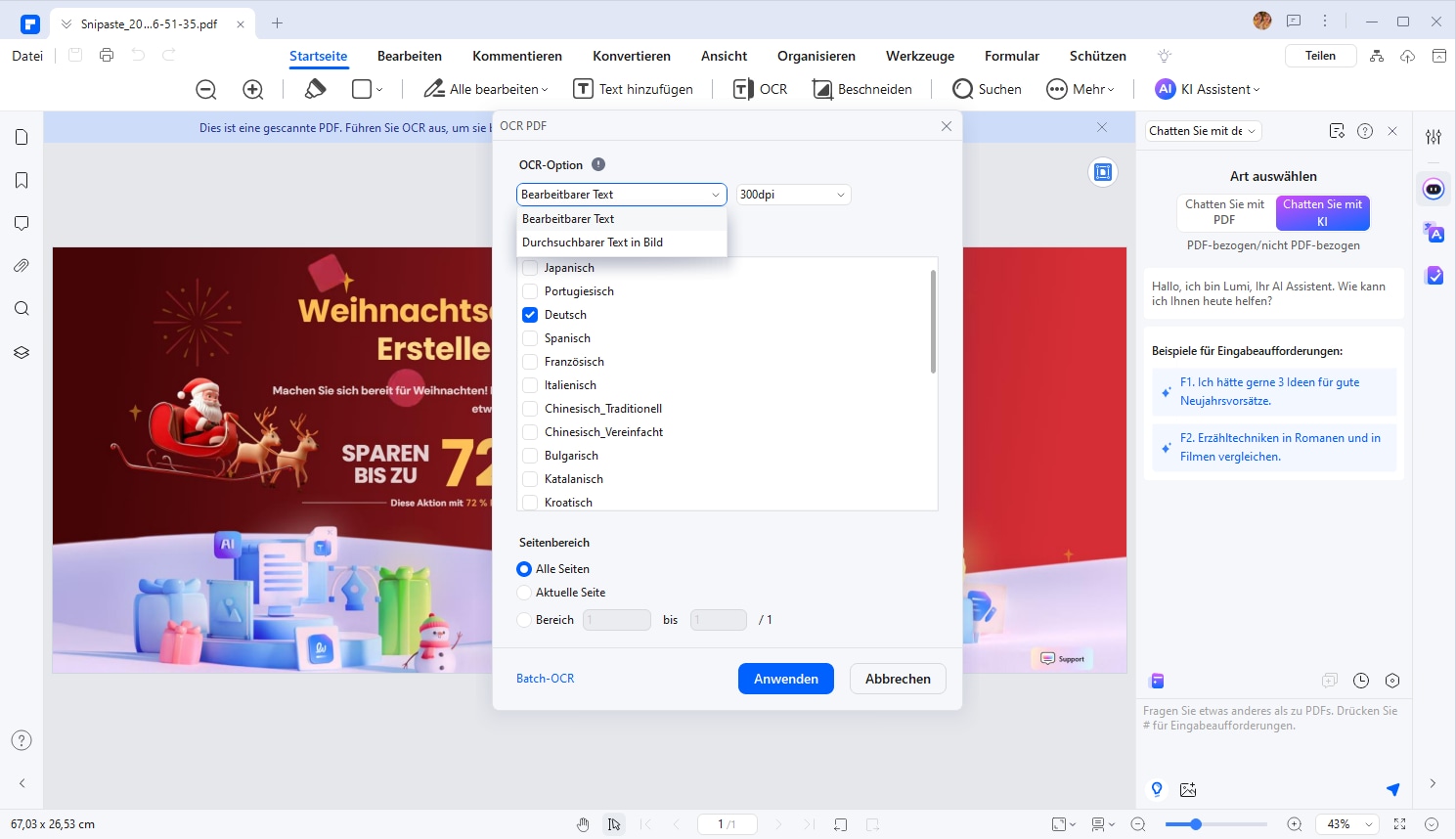
Schritt 3: Wählen Sie die Einstellungen
Wählen Sie „Bild in bearbeitbaren Text konvertieren“ Wählen Sie die Sprache, in der der Text auf dem Bild geschrieben ist. Klicken Sie auf die "Anwenden"-Schaltfläche, um die OCR-Erkennung zu starten.
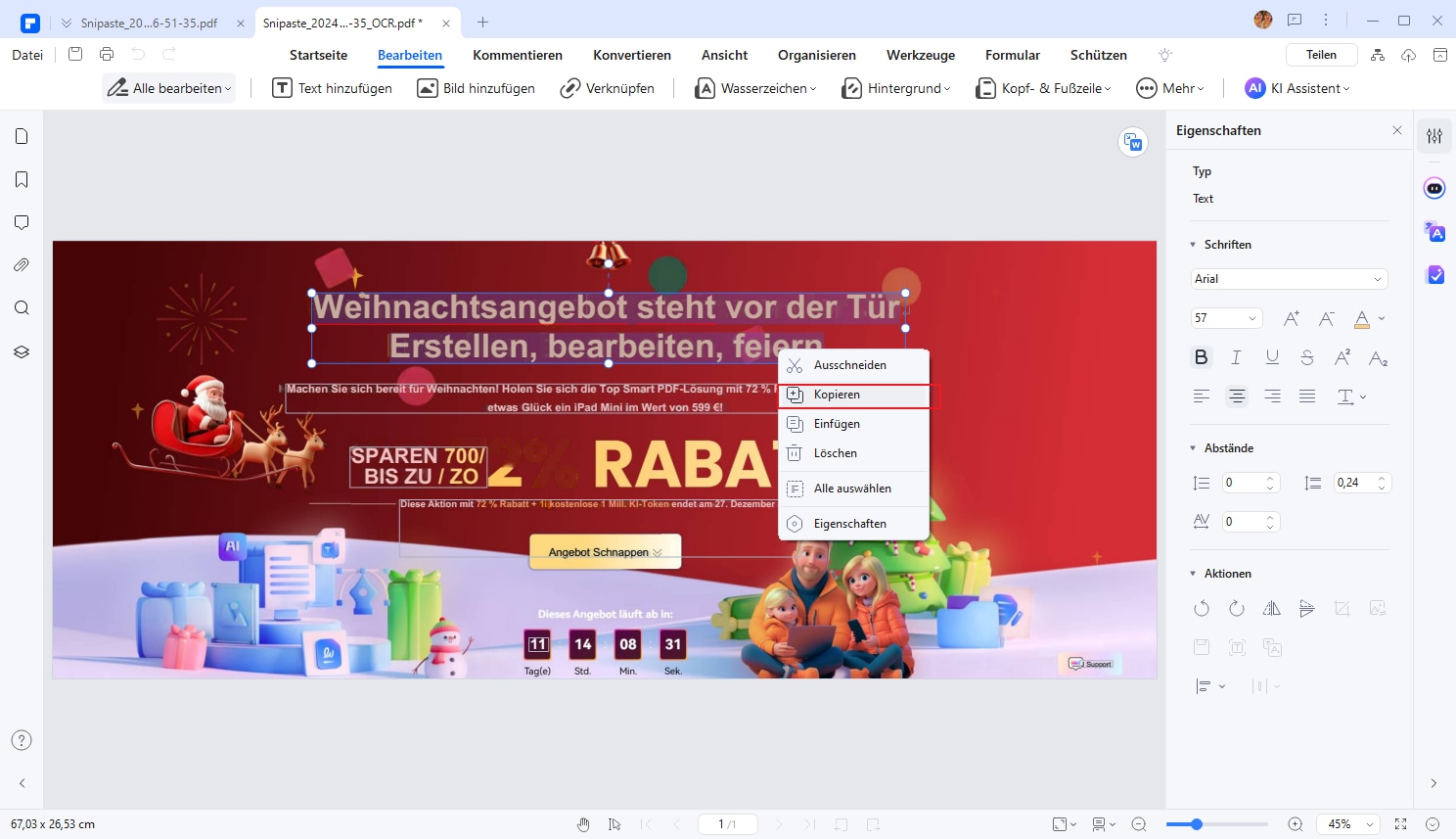
Schritt 4: Überprüfen Sie den erkannten Text
Überprüfen Sie den erkannten Text auf Fehler und korrigieren Sie ihn gegebenenfalls. Kopieren Sie den erkannten Text in ein Dokument oder eine andere Anwendung.
FAQs zum Kopieren vom Text aus gescannten PDF
1. Warum kann ich keinen Text aus einer gescannten PDF-Datei kopieren?
Gescannte PDF-Dateien sind im Wesentlichen Bilddateien und enthalten keinen durchsuchbaren oder bearbeitbaren Text. Um Text aus einer gescannten PDF-Datei zu kopieren, muss sie zunächst mit einer OCR-Software (Optical Character Recognition) in ein textbasiertes Format umgewandelt werden. Ohne diese Umwandlung kann der Text nicht erkannt oder zum Kopieren ausgewählt werden.
2. Wie kann ich Text aus einer gescannten PDF-Datei extrahieren?
Es gibt mehrere Möglichkeiten, Text aus einer gescannten PDF-Datei zu extrahieren. Eine Möglichkeit ist die Verwendung einer OCR-Software (optische Zeichenerkennung) wie PDFelement. Das OCR-Tool kann das Bild analysieren und den gescannten Text in bearbeitbaren und durchsuchbaren digitalen Text umwandeln. Eine andere Möglichkeit ist die Nutzung eines Online-OCR-Dienstes wie Smallpdf oder Online OCR, der ebenfalls gescannte Bilder in bearbeitbaren Text umwandeln kann. Dabei ist jedoch zu beachten, dass die Qualität der OCR aufgrund von Problemen wie Bildqualität, Formatierung oder Spracherkennungsfehlern manchmal nicht perfekt ist.
3. Wie kopiere ich Text aus einer gescannten PDF-Datei auf Mac?
Um Text aus einer gescannten PDF-Datei auf dem Mac zu kopieren, müssen Sie eine OCR-Software verwenden, die auf dem Mac funktioniert. Sie können z. B. PDFelement auf dem Mac installieren und dann einfach die gescannte PDF-Datei im PDF-Editor öffnen und die gescannten Bilder in bearbeitbaren Text umwandeln lassen. Sobald der OCR-Prozess abgeschlossen ist, können Sie den gewünschten Text wie bei jedem anderen Dokument auswählen und kopieren.
4. Wie extrahiere ich Text aus einer gescannten PDF-Datei in Acrobat?
Es ist ganz einfach, Text aus einem gescannten PDF-Dokument in Adobe Acrobat zu extrahieren, und zwar wie folgt
Öffnen Sie die gescannte PDF-Datei in Acrobat und klicken Sie im rechten Fensterbereich auf "PDF bearbeiten". Acrobat erkennt, dass es sich um ein gescanntes PDF handelt und wendet OCR auf das PDF an, wodurch die Datei in eine vollständig bearbeitbare Version umgewandelt wird.
Jetzt können Sie Text aus der PDF-Datei kopieren und einfügen. Oder Sie können die PDF-Datei als bearbeitbares Word oder Text exportieren.
Fazit
Das Kopieren von Text aus gescannten PDFs ist mit den richtigen Tools und Methoden kein Problem mehr. Ob offline mit Wondershare PDFelement oder online mit HiPDF und Google Drive – die vorgestellten Optionen bieten Lösungen für jeden Bedarf.
Machen Sie den nächsten Schritt und testen Sie Wondershare PDFelement, um Ihre PDF-Bearbeitungsaufgaben effizienter zu gestalten. Holen Sie sich die kostenlose Testversion und überzeugen Sie sich selbst!
Kostenlos Downloaden oder PDFelement kaufen jetzt sofort!
Kostenlos Downloaden oder PDFelement kaufen jetzt sofort!
PDFelement kaufen jetzt sofort!
PDFelement kaufen jetzt sofort!

Noah Hofer
staff Editor