
PDFelement - Leistungsstarker und einfacher PDF-Editor
Starten Sie mit der einfachsten Art, PDFs zu verwalten - mit PDFelement!
Die Optical Character Recognition (OCR) ist eine Technologie, mit der Sie Text aus Bildern extrahieren können. OCR kann gedruckte oder handschriftliche Zeichen auf Bildern erkennen und die Zeichen extrahieren. Anschließend können Sie den extrahierten Text mit anderen Anwendungen, z.B. einem Texteditor, bearbeiten und weitergeben.
Viele Tools unterstützen OCR. Die meisten kommerziellen OCR-Engines sind jedoch nicht kostenlos oder haben Einschränkungen bei der kostenlosen Nutzung. Glücklicherweise können Sie dank der Bemühungen vieler Forscher und der Open-Source-Community mehrere großartige Open-Source-OCR-Engines Gratis Testen oder verwenden.
Python ist eine einfach zu bedienende und effiziente Programmiersprache, die besonders in der Text- und Bildverarbeitung beliebt ist. Mit einer Vielzahl von Bibliotheken kann Python automatisch verschiedene Aufgaben für Sie erledigen, einschließlich der Umwandlung von Bildern in Text. Dieser Artikel beschreibt, wie Sie Python mit zwei beliebten OCR-Engines verwenden, um Text aus Bildern zu extrahieren.
In diesem Artikel
Wie man mit Python Text aus Bildern extrahiert
Tesseract verwenden
Tesseract ist eine beliebte Open-Source-OCR-Engine, die für die Unterstützung von mehr als 100 Sprachen programmiert wurde. In diesem Artikel verwenden wir Python-Tesseract (pytesseract), einen Python-Wrapper für Tesseract, mit dem Sie Tesseract mit Python verwenden können. Alle in diesem Artikel beschriebenen Schritte werden auf einem Windows-PC durchgeführt.
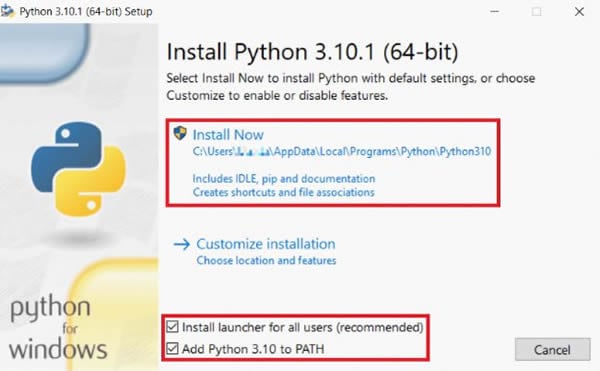
Schritt 1 Laden Sie Python herunter und installieren Sie es.
Python 3.6+ ist erforderlich, um pytesseract zu verwenden. Stellen Sie also sicher, dass Sie eine neuere Version als 3.6 installieren. Wählen Sie dann im Installationsfenster "Python X.XX zu PATH hinzufügen", um Python automatisch zu Ihrem Systempfad hinzuzufügen. Andernfalls müssen Sie den Systempfad nach der Installation von Python manuell konfigurieren.
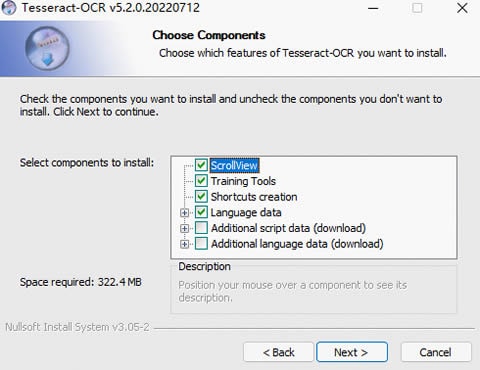
Schritt 2 Laden Sie Tesseract herunter und installieren Sie es.
Sie können das neueste Installationspaket von Tesseract für Windows hier herunterladen. Wählen Sie dann im Installationsfenster die zusätzlichen Sprachen und Skripte aus, die Sie installieren möchten. Standardmäßig können Sie nur die englische Sprache installieren.
Tesseract bietet ein praktisches Kommandozeilen-Tool, mit dem Sie OCR an Bildern durchführen können. Nachdem Sie Tesseract installiert haben, öffnen Sie ein CLI-Fenster, navigieren zu dem Ordner, in dem sich die Bilddatei befindet, deren Text Sie extrahieren möchten und führen den folgenden Befehl aus:
tesseract
Dieser Befehl extrahiert Text aus dem angegebenen Bild und speichert den Text in der Datei out.txt. Um Tesseract mit Python zu verwenden, fahren Sie mit dem nächsten Schritt fort, um die erforderlichen Python-Pakete zu installieren.
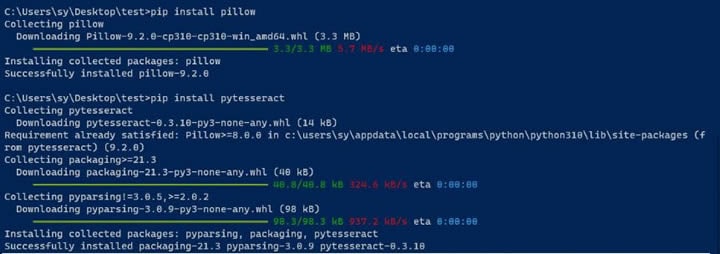
Schritt 3 Installieren Sie die Pakete Pillow und pytesseract.
Pillow wird verwendet, um Bilder zu verarbeiten und pytesseract wird benötigt, um Tesseract mit Python zu verwenden. Sie können die Pakete installieren, indem Sie die folgenden Befehle in einem CLI-Fenster ausführen:
pip install pillow
pip install pytesseract
Schritt 4 Schreiben Sie Python-Code, um Text aus Bildern zu extrahieren.
Nachdem Sie die Pakete installiert haben, können Sie nun Ihren Python-Code schreiben, um Text aus Bildern zu extrahieren. Gehen Sie zu dem Ordner, in dem die Bilddateien gespeichert sind, aus denen Sie Text extrahieren möchten. Erstellen Sie eine Textdatei und ändern Sie ihren Namen in extract.py. Sie können die Textdatei in einen beliebigen Namen umbenennen, aber achten Sie darauf, dass die Dateinamenerweiterung py lautet.
Verwenden Sie einen Texteditor wie Notepad, um die extract.py Datei zu öffnen. Kopieren Sie den folgenden Beispielcode in die Datei und speichern Sie die Datei:
from PIL import Image
import pytesseract
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
print(pytesseract.image_to_string(Image.open('test.jpg')))
Um das vorstehende Skript erfolgreich auszuführen, müssen Sie eine Bilddatei mit dem Namen test.jpg im selben Ordner wie die Datei extract.py haben. Dieser Artikel verwendet das folgende Bild als Beispiel.

Öffnen Sie ein CLI-Fenster, gehen Sie zu dem Ordner, in dem sich die Bilddatei befindet und führen Sie dann den folgenden Befehl aus:
python extract.py
Sie sollten die folgende Befehlsausgabe erhalten.
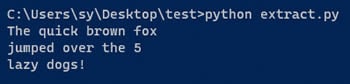
Die Ausgabe zeigt, dass der Text erfolgreich aus dem Bild extrahiert wurde. Damit ist der grundlegende Prozess der Verwendung von Tesseract mit Python abgeschlossen. Weitere Informationen zur Verwendung von pytesseract finden Sie in der Dokumentation des Programms.
Wenn Sie Text aus mehreren Bildern in einem Stapel extrahieren möchten, können Sie die Namen der Dateien einfach in eine TXT-Datei einfügen, z.B. images.txt. Zum Beispiel:
test.jpg
test1.jpg
Ändern Sie dann die Datei extract.py wie folgt:
from PIL import Image
import pytesseract
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
print(pytesseract.image_to_string('images.txt'))
Wenn Sie das obige Skript ausführen, wird der Text aus allen Bildern extrahiert, die in der Datei images.txt angegeben sind.
EasyOCR verwenden
EasyOCR ist ein Python-Paket, das eine gebrauchsfertige OCR-Engine bereitstellt und über 80 Sprachen unterstützt. EasyOCR ist leicht zu installieren und sehr einfach zu bedienen. Das macht es zu einer großartigen Lösung für die Durchführung von OCR mit Python. Sie müssen nur die Pakete PyTorch (nur unter Windows erforderlich) und EasyOCR installieren und schon können Sie mit Python Text aus Bildern extrahieren.
Schritt 1 Installieren Sie die erforderlichen Python-Pakete.
Um EasyOCR unter Windows zu verwenden, müssen Sie die Pakete PyTorch und EasyOCR installieren. Führen Sie die folgenden Befehle nacheinander aus, um die Pakete zu installieren:
pip install torch torchvision torchaudio
pip install easyocr
pip install torch torchvision torchaudio
pip install easyocr
Schritt 2 Schreiben Sie Python-Code zur Verwendung von EasyOCR.
Gehen Sie in den Ordner, in dem sich Ihr Bild befindet, erstellen Sie eine .py-Datei, z.B. extract.py, und kopieren Sie dann den folgenden Beispielcode in die Datei:
import easyocr
reader = easyocr.Reader(['en'])
result = reader.readtext('test.jpg', detail = 0)
print(result)
Die folgende Abbildung zeigt die Befehlsausgabe, wenn Sie die Datei extract.py ausführen.

Wie Sie in der Befehlsausgabe sehen, wird der Text aus dem Testbild extrahiert.
Vorteile und Nachteile der Verwendung von Python
Python ist eine Programmiersprache, die leicht zu erlernen und anzuwenden ist. Es wird häufig für Deep Learning und die Verarbeitung natürlicher Sprache verwendet. Im Vergleich zu anderen Sprachen ist Python-Code oft einfacher und kürzer. Es braucht jedoch Zeit, Python zu lernen, und Sie müssen die OCR-Engines, die Sie mit Python verwenden möchten, recherchieren.
Vorteile der Verwendung von Python zum Extrahieren von Text aus Bildern:
- OCR-Engines wie Tesseract und EasyOCR können kostenlos verwendet werden.
- Python eignet sich für Stapel und sich wiederholende OCR-Aufgaben.
- Es ist effizient und schnell, eine große Anzahl von Bildern mit Python zu verarbeiten.
- Sie können solide Konvertierungsergebnisse erzielen, indem Sie die Optionen der OCR-Engine optimieren .
- Sie können Ihr gut gestaltetes Python-Skript speichern und es immer dann verwenden, wenn Sie Text aus Bildern extrahieren müssen. Sie können das Skript auch mit anderen teilen, die die gleichen Konvertierungsanforderungen haben.
Nachteile der Verwendung von Python zum Extrahieren von Text aus Bildern:
- Python-Kenntnisse sind erforderlich.
- Recherchieren Sie die OCR-Engines, die Sie verwenden möchten.
- Open-Source OCR-Engines sind möglicherweise nicht so genau wie kommerzielle. Außerdem sind manche nicht in der Lage, Handschrift zu erkennen.
Trotzdem ist es immer gut, etwas Neues zu lernen. Darüber hinaus können Sie bei Bedarf jederzeit zu anderen Tools wechseln. Es gibt eine Vielzahl von Tools, mit denen Sie schnell Text aus Bildern extrahieren können. Sie können je nach Ihren Anforderungen wählen.
Wie man ohne Python Text aus Bildern extrahiert
Wenn Sie kein Fan von Programmierung sind und nach einem sofort einsetzbaren Tool suchen, ist Wondershare PDFelement - PDF Editor eine schnelle und einfache App, die Sie sich ansehen sollten.
PDFelement ist ein schneller und vielseitiger PDF-Editor, mit dem Sie PDFs anzeigen, bearbeiten und konvertieren können. PDFelement ist außerdem mit einer fortschrittlichen OCR-Engine ausgestattet, mit der Sie Text präzise und effizient aus Bildern extrahieren können.
 G2-Wertung: 4.5/5 |
G2-Wertung: 4.5/5 |  100 % Sicher |
100 % Sicher |
 G2-Wertung: 4.5/5 |100 % Sicher |
G2-Wertung: 4.5/5 |100 % Sicher |
Sie können diese Schritte befolgen, um Text aus Bildern in PDFelement zu extrahieren:
Schritt 1 Öffnen Sie PDFelement. Ziehen Sie die Bilddatei, aus der Sie Text extrahieren möchten, per Drag & Drop in das PDFelement Fenster. Sie können auch PDF erstellen > Aus Datei wählen und die Bilddatei auswählen. Anschließend wandelt PDFelement das Bild in eine PDF-Datei um und öffnet sie in einer neuen Registerkarte.
Schritt 2 Klicken Sie im Tool Menü auf OCR, um das Bild mit OCR zu bearbeiten. Dies ermöglicht es PDFelement, alle Zeichen im Bild zu erkennen und sie in bearbeitbaren und durchsuchbaren Text umzuwandeln.
Schritt 3 Kopieren Sie den Text an die gewünschte Stelle und bearbeiten Sie den Text. Sie können das PDF mit bearbeitbarem Text auch in andere Formate wie Word oder Excel konvertieren.
Neben der OCR-Engine bietet PDFelement auch andere Funktionen, die Ihre Produktivität steigern können:
- Öffnen und betrachten Sie PDF-Dateien mit hoher Geschwindigkeit
- Bearbeiten Sie Inhalte in PDF-Dateien, z.B. Text und Bilder.
- PDFs in verschiedene Formate konvertieren, z.B. EPUB und Word
Fazit
Python ist eine hervorragende Programmiersprache, die sich für die Automatisierung von sich wiederholenden Aufgaben eignet. Mithilfe von Python können Sie mit Open-Source-OCR-Engines einfach und schnell Text aus Bildern extrahieren. Dieser Artikel beschreibt, wie Sie die OCR-Funktionen von Tesseract und EasyOCR mit Python nutzen können.
Das Extrahieren von Text aus Bildern mit Python erfordert jedoch eine Programmierung, die grundlegende Programmierkenntnisse und die Sprache Python voraussetzt. Wenn Sie keine Programmierkenntnisse haben, gibt es viele andere Möglichkeiten, Text aus Bildern zu extrahieren. Eine gute Option ist PDFelement, eine fortschrittliche und hochentwickelte Anwendung, mit der Sie einfach und effizient Text aus Bildern extrahieren können.
