
PDFelement - Leistungsstarker und einfacher PDF-Editor
Starten Sie mit der einfachsten Art, PDFs zu verwalten - mit PDFelement!
Mit der optischen Zeichenerkennung (OCR) können Sie ein gescanntes Dokument in eine bearbeitbare und durchsuchbare Textdatei umwandeln. Es gibt verschiedene Anwendungen, die zum Teil mit Open-Source-Tools durchgeführt werden können.
Open Source ist eine praktikable Option für alle, die die OCR nach ihren Bedürfnissen anpassen möchten. Wenn Sie ein hervorragendes OCR Open Source Tool suchen, haben wir das Richtige für Sie. In diesem Artikel lernen Sie die besten Tools für Online-OCR kennen und erfahren, warum man sie braucht. Legen wir los!

Warum braucht man ein Open Source OCR Tool?
Einige der Gründe, warum man ein Open-Source OCR Tool braucht, sind:
- Wenn Sie OCR an Ihre Bedürfnisse anpassen möchten, benötigen Sie eine Open-Source-OCR.
- Da Open-Source-OCR flexibler und modifizierbarer ist als die OCR-Tools, können Sie damit besser arbeiten, wenn Sie dem Programm später etwas Innovatives hinzufügen möchten.
- Da die meisten OCR-Programme kostenpflichtig sind, werden Sie kein Abonnement erwerben wollen, wenn Sie die Software nur ein- oder zweimal pro Monat benötigen. In diesem Szenario könnten Sie eine Open-Source-OCR-Software für diese Aufgabe benötigen.
Die 4 besten Open Source OCR Tools im Jahr 2023
Jetzt, da Sie wissen, warum Sie Open Source OCR-Software benötigen, suchen Sie vielleicht nach der besten Option. Genau das finden Sie in diesem Abschnitt. Hier haben wir die besten Open-Source-Tools für die OCR von PDF überprüft, darunter:
1. Tesseract OCR
Tesseract von Hewlett-Packard gilt weithin als die beste Open-Source-OCR-Engine. Es handelt sich um Open-Source-Software, die unter der Apache-Lizenz veröffentlicht wird und seit 2006 von Google unterstützt wird. Die Tesseract OCR-Engine ist außerdem eine der präzisesten und am besten zugänglichen Open-Source-Lösungen. Die neueste stabile Version von Tesseract, 4.1.1, basiert auf LSTM und kann Text in bis zu 116 Sprachen verarbeiten.
Da Tesseract über die Befehlszeile (CIL) ausgeführt wird, verfügt es nicht über eine grafische Oberfläche (GUI). Mit der fortschrittlichen Bildvorverarbeitung und den Lernfähigkeiten eines neuronalen Netzwerks kann es neue Erkenntnisse gewinnen. Außerdem spielen Sprache, Bildqualität, Datentraining, Seitensegmentierung und Engine eine Rolle dabei, wie genau das Ergebnis ist.
Bilder können mit Bibliotheken wie OpenCV und ImageMagick vorverarbeitet werden, um Rauschen zu entfernen, die Größe zu ändern, zu binarisieren, zu drehen, zu invertieren, zu erweitern und zu erodieren, um präzisere Ergebnisse mit diesem Open Source OCR Python Tool zu erzielen.
Wichtigste funktionen
- Das Tool funktioniert mit vielen Sprachen und hat Wrapper für viele von ihnen, darunter Java, Python, Ruby und Swift.
- Es ist mit anderen Programmen zur Erstellung von GUIs kompatibel.
- Um Bilder zu laden, konsultiert die Engine eine Open-Source-OCR-Bibliothek wie Leptonica.
- Es bietet den Menschen viele Möglichkeiten, sich in ihren Communities zu engagieren.
- Unterstützte Sprachen: 116 Sprachen, darunter Englisch, Spanisch, Hindi, Polnisch, Portugiesisch und andere.
Vorteile
Unterstützt mehrere Programmiersprachen
Bessere Genauigkeit als die Konkurrenz
Nachteile
Für Anfänger schwer zu verstehen
Um eine Open-Source-PDF-OCR mit Tesseract OCR durchzuführen, folgen Sie den nachstehenden Schritten:
Schritt 1 Holen Sie sich zunächst das neueste Installationsprogramm für Tesseract. Öffnen Sie die Eingabeaufforderung und geben Sie "pip install pytesseract" ein, um es zu installieren.
Schritt 2 Jetzt müssen Sie das Bild lesen. Gehen Sie zu Google Colab und geben Sie den folgenden Code ein: "In cmd=r". Sie müssen den Pfad von tesseract.exe auf Ihrem Computer angeben. In cv2.imread müssen Sie den Namen des Bildes angeben, das Sie in Colab hochgeladen haben.

Schritt 3 Nachdem Sie das Bild gelesen haben, ist es an der Zeit, den Bildtext in eine Zeichenkette zu konvertieren. Dazu müssen Sie das folgende Stückchen Code hinzufügen:

Schritt 4 Wenn Sie den Code ausführen, erhalten Sie den Bildtext als Ausgabe.
2. Azure OCR
Die Azure OCR-API in der Cloud bietet Programmierern Zugriff auf fortschrittliche Algorithmen zur Texterkennung, die strukturierte Daten aus gescannten Fotos liefern. Mit den OCR-Tools von Microsoft Azure können Sie gedruckte Schrift in mehreren Sprachen, handgeschriebenen Text in vielen Sprachen und Währungssymbole aus Bildern, Zahlen und mehrseitigen PDF-Broschüren auslesen.
Der Azure Cognitive Service, Computer Vision, ist ein Dienst der künstlichen Intelligenz (KI), der Standbilder und bewegte Bilder nach relevanten Informationen auswertet. Zu den vielen Funktionen, die Azure OCR bietet, gehört der Zugang zu Azure Cognitive Services, einer Computer Vision API.
Unterstützte Sprachen: Mehr als 10 Sprachen, darunter Englisch, Japanisch, Spanisch, etc.
Wichtigste funktionen
- Es stehen drei Cloud-Dienste zur Verfügung und Sie können vergleichen, wie gut deren OCR-Algorithmen funktionieren.
- So können Entwickler ganz einfach vorgefertigte KI-Funktionen zu ihrer Software hinzufügen.
- Aufgrund der Portabilität von Containern können Sie dieselben umfangreichen APIs nutzen, die auch in Azure verfügbar sind.
- Informationen in verschiedenen Sprachen und Schriften, gedruckt und handschriftlich, können abgerufen werden.
Vorteile
KI-basierte Skripte für OCR
Angemessene Präzision
Nachteile
Schwierig für normale Benutzer
Um die OCR mit Azure OCR durchzuführen, folgen Sie den nachstehenden Schritten:
Schritt 1 Besuchen Sie das Azure-Portal mit Ihrem bevorzugten Browser. Um auf die kognitiven Dienste zuzugreifen, gehen Sie zum Abschnitt KI + Maschinelles Lernen unter "Alle Dienste" im Hauptmenü.
Schritt 2 Wählen Sie Computer Vision, Erstellen, und richten Sie das Formular ein.
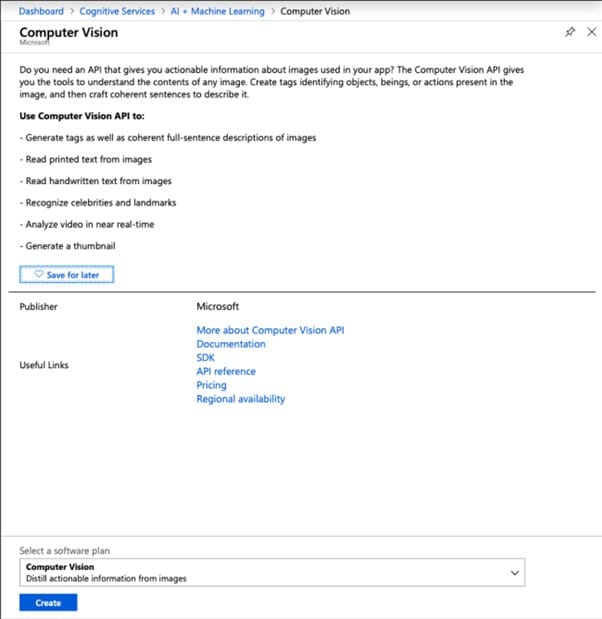
Schritt 3 Um auf die OCR-Test Ressource zuzugreifen, rufen Sie das Dashboard auf. Um auf Keys zuzugreifen, wählen Sie es aus dem Untermenü die Ressourcenverwaltung.
Schritt 4 Es werden zwei Keys angezeigt; bitte kopieren Sie KEY 1. Schreiben Sie den folgenden Code in Google Colab.
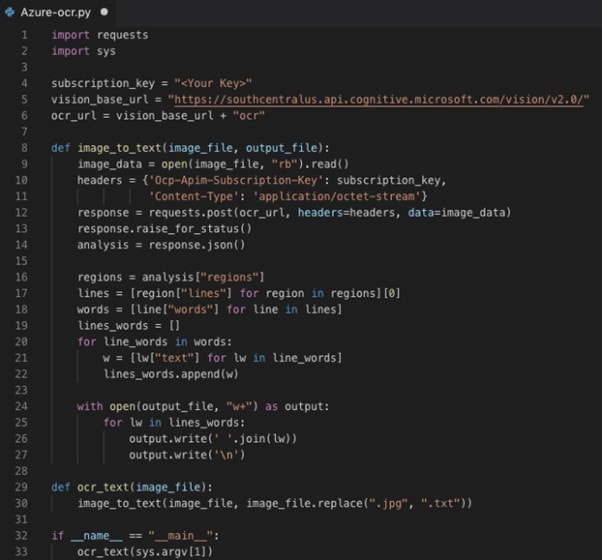
Schritt 5 Der Code liefert bei seiner Ausführung eine Textausgabe auf der Konsole, nämlich den aus dem Bild extrahierten Text.
3. Abbyy OCR
Schritt 5 Der Code liefert bei seiner Ausführung eine Textausgabe auf der Konsole, nämlich den aus dem Bild extrahierten Text. Das Tool verfügt über eine Spracherkennungskapazität von über 200. Mit Hilfe dieses Programms können Sie PDF-/Bilddateien in Word-, Excel-, PDF-, etc. Formate konvertieren, in denen Sie Text suchen können. Erkannte Informationen werden in XML (Extensible Markup Language) umgewandelt. Diese Ressource ist eine Java-, .NET-, iOS- und Python-Bibliothek.
Sie können Dokumente mit Anmerkungen und Markierungen versehen, Sicherheitsmaßnahmen wie Passwörter und digitale Signaturen hinzufügen, Dokumente damit überprüfen und vieles mehr. Die zeitsparenden Funktionen der App erleichtern es, gemeinsam an Projekten zu arbeiten.
Unterstützte Sprachen: Funktioniert mit 200 Sprachen, darunter Russisch, Hebräisch, Chinesisch, Farsi und andere.
Wichtigste funktionen
- Kompatibel mit verschiedenen Sprachen, darunter Japanisch, Koreanisch, Arabisch, Farsi, Vietnamesisch und Thai.
- Sie können Ihre Dokumente in Word, Excel oder PowerPoint exportieren.
- Legen Sie das resultierende Archiv in einem Cloud-Speicherdienst wie Google Drive ab.
- Die Benutzeroberfläche ist schlank und intuitiv, so dass es ein Kinderspiel ist, Änderungen vorzunehmen und Dateien anzuordnen.
Vorteile
Schnell und zügig
Einfache Zusammenarbeit
Nachteile
Ziemlich teuer
4. OCR Space
Wenn Sie gescannte Fotos oder PDFs in bearbeitbare Dokumente umwandeln möchten, sind Sie bei OCR Space an der richtigen Adresse. Es ist ein webbasiertes, kostenloses OCR Tool, das vier verschiedene OCR-Engines einsetzt, um Text aus Fotos und PDFs zu ziehen und ihn in einem Overlay anzuzeigen. OCR Space ist ein benutzerfreundliches Online-Tool zur Umwandlung gescannter Dokumente und PDFs in bearbeitbaren Text, der digital durchsucht werden kann.
Um ein Dokument in bearbeitbare Dateien zu konvertieren, können Sie die Datei entweder hochladen oder die URL einfügen. Das Programm kann feststellen, wann ein Bild vergrößert werden muss und tut dies automatisch.
Unterstützte Sprachen: Mehr als 20 Sprachen, darunter Englisch, Hindi, Russisch, Spanisch, etc.
Wichtigste funktionen
- Scannen Sie schnell Dokumente, auch komplizierte Tabellenlayouts, wie z.B. Quittungen.
- Sie können herausfinden, wie ein Bild ausgerichtet ist und es automatisch drehen, wenn es falsch ist.
- Es unterstützt Dateien mit schlecht kontrastiertem Text vor einem komplizierten Hintergrund.
- Maximieren Sie die OCR-Genauigkeit durch automatische Vergrößerung von Bilddateien oder Dokumenteninhalten.
Vorteile
Vollständig online
Keine Anmeldung erforderlich
Nachteile
Ausgabe in Word-Dokument kann nicht generiert werden
Um eine OCR mit OCR Space durchzuführen, folgen Sie den nachstehenden Schritten:
Schritt 1 Gehen Sie zu OCR Space und wählen Sie ein Bild oder eine PDF-Datei von Ihrem Computer aus, indem Sie auf die Schaltfläche "Datei auswählen" klicken. Bilder in den Formaten PNG, JPG und WebP werden alle von OCR Space unterstützt. Sie können auch die URL der Quelldatei des Bildes oder PDFs eingeben oder einfügen.
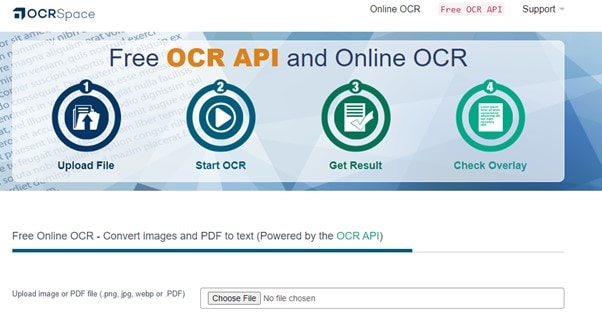
Schritt 2 Klicken Sie auf die Registerkarte Sprache, um die Sprache entsprechend dem Text im Bild oder PDF einzustellen. Bevor Sie mit der OCR beginnen, haben Sie drei Möglichkeiten, aus denen Sie wählen können. Wählen Sie die Optionen entsprechend Ihren Anforderungen.
Schritt 3 Wenn Sie die Engines neben der Option "Zu verwendende OCR-Engine auswählen" ausgewählt haben, klicken Sie auf "OCR starten", um den Scanvorgang zu beginnen.
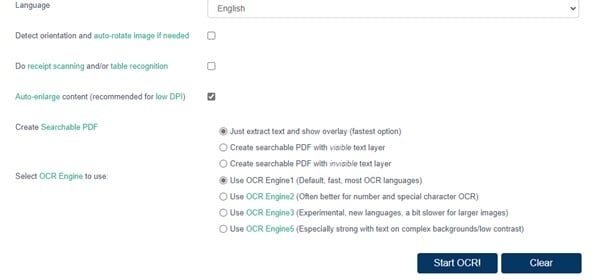
Schritt 4 Nach Abschluss des Vorgangs erhalten Sie eine Ausgabe in Textform neben dem Bild oder der PDF-Datei. Sie können Änderungen vornehmen, Download wählen oder kopieren und in einen Texteditor einfügen.
Bestes Tool für PDF-OCRs unter Windows und iOS
Möchten Sie das beste Tool für PDF OCR für Windows- und iOS-Geräte finden? Sie finden es in diesem Abschnitt. Obwohl die oben genannten Tools die besten für Open-Source-OCR sind, können sie PDFs nicht in jeder Situation bearbeiten. Dafür benötigen Sie hochwertige Software, wie z.B. Wondershare PDFelement - PDF Editor.
PDF eignet sich für die Bearbeitung aller PDF-Anforderungen. Benutzer können gescannte Dokumente einfach bearbeiten und profitieren von der Möglichkeit, OCR-erkannte Texte in gängige Formate zu konvertieren, darunter Microsoft Word, Excel, HTML und PowerPoint. Anpassbare Textfelder, Stempel und Kommentare sind ebenfalls Teil des Tools. Die Erstellung von Inhalten im Team ist mit diesem Tool ein Kinderspiel.
 G2-Wertung: 4.5/5 |
G2-Wertung: 4.5/5 |  100 % Sicher |
100 % Sicher |
 G2-Wertung: 4.5/5 |100 % Sicher |
G2-Wertung: 4.5/5 |100 % Sicher |Wichtigste Funktionen
- Bilder und gescannte Dokumente mit Text darin können erkannt werden.
- Damit können Sie Text aus einer gescannten PDF-Datei oder einem Bild extrahieren und für andere Zwecke wie Kopieren oder Suchen verwenden.
- Schnelle Verarbeitungszeiten und umfangreiche Bearbeitungstools ermöglichen es Ihnen, ein PDF zu erstellen, das sich von anderen abhebt.
- Dank der benutzerfreundlichen Oberfläche finden sich auch Anfänger schnell zurecht.
Was wir mögen
Einfaches Durchsuchen von Text in PDF
Kann das OCR-Ergebnis in ein Word-Format konvertieren
Richtiges Tool zur Anpassung
Was wir nicht mögen
Sie können einige Bearbeitungsfunktionen nicht kostenlos nutzen
Preise: Kostenlos bis $7,99
Unterstützte Sprachen: Es werden bis zu 29 verschiedene Sprachen unterstützt.
Um eine PDF-OCR über PDFelement durchzuführen, folgen Sie den nachstehenden Schritten:
Schritt 1 Holen Sie PDFelement auf Ihr Gerät und starten Sie es. Klicken Sie auf das + Symbol oder ziehen Sie Ihre PDF-Datei per Drag & Drop, um sie hochzuladen.
G2-Wertung: 4.5/5 | 100 % Sicher |
G2-Wertung: 4.5/5 |100 % Sicher |
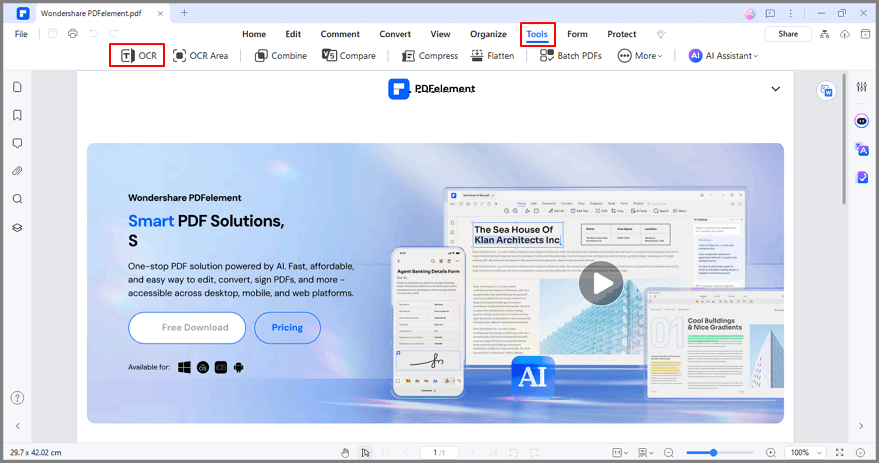
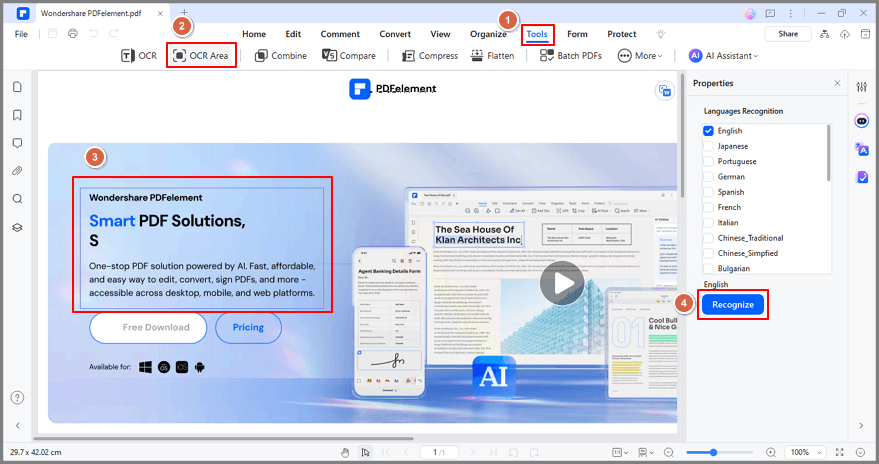
Schritt 2 Klicken Sie auf Tool und dann auf OCR, um fortzufahren. Es erscheint ein Fenster. Wählen Sie "Editierbarer Text" und wählen Sie dann die Sprache, indem Sie auf "Sprache wählen" klicken. Klicken Sie dann auf OK, um die Überprüfung zu starten.
Schritt 3 Nach dem Scannen können Sie auf "Bearbeiten" klicken, um den PDF-Text zu bearbeiten, oder auf "In Text", um den bearbeitbaren Text auf Ihren Computer zu exportieren.
Fazit
Mit Open-Source OCR-Tools können Sie ganz einfach Text aus Bildern und PDFs extrahieren, ohne die Software herunterladen zu müssen. Außerdem kann der Benutzer das Tool nach seinen Bedürfnissen anpassen. Wir hoffen, dass Sie mit den in diesem Artikel vorgestellten OCR Open Source Tools das richtige gefunden haben. Und wenn Sie PDF-OCR auf einem Windows- oder iOS-Gerät durchführen möchten, ist unsere Top-Empfehlung PDFelement.
